Architecture
Feb 4, 2020
Storage Balance and Data Migration
Heng Chen
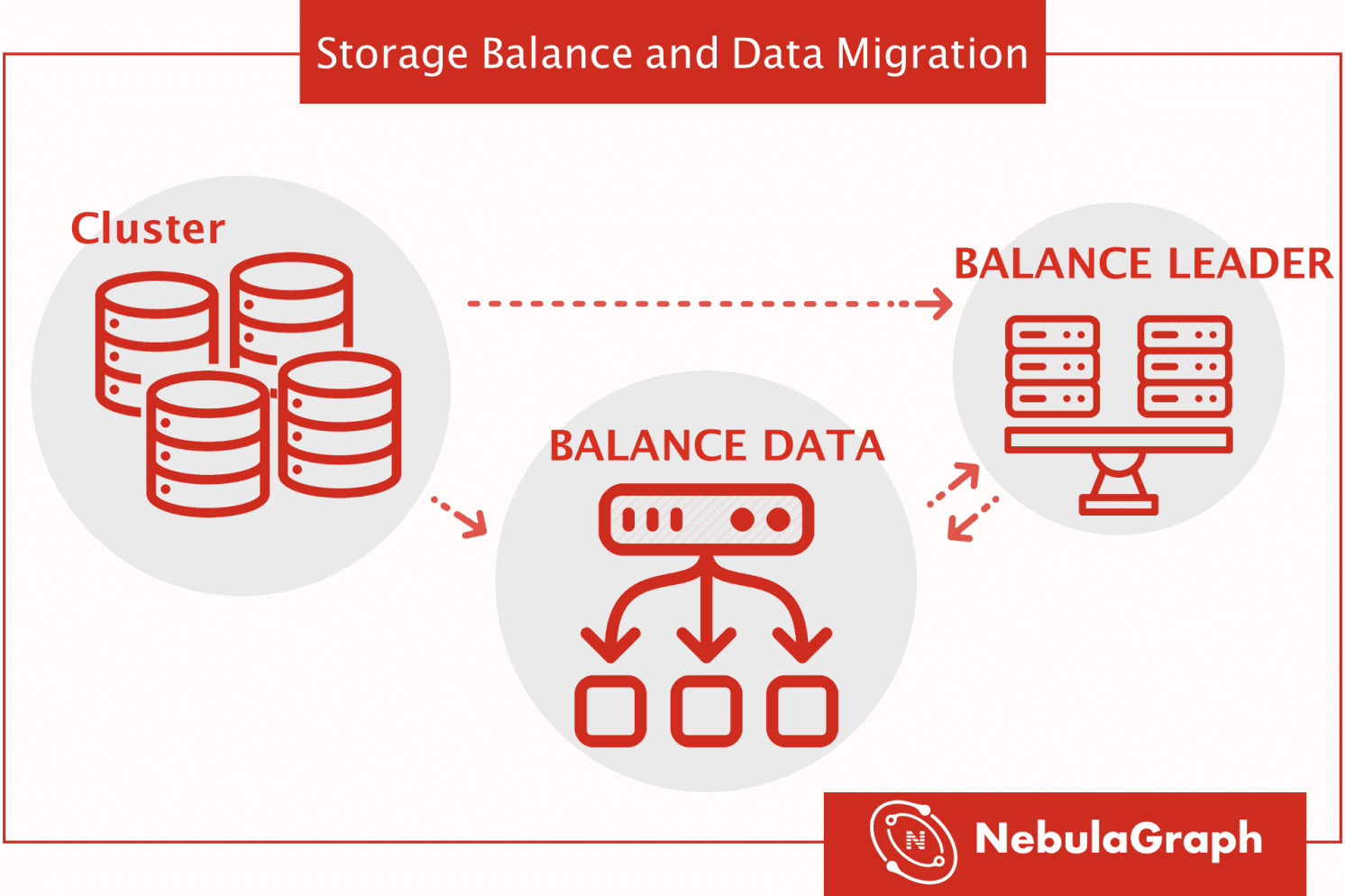
In our post Storage Design we mentioned the distributed kv store is managed by the meta service. Both the partition distribution and machine status can be found in the meta service. Users can use commands in the console to add or remove machines to execute a balance plan for the storage service.
NebulaGraph's service is composed of three parts: graph, storage and meta. In this post, we will introduce how to implement data (partition) and work-load balance in the storage service.
The storage service can be scaled in or out horizontally by the BALANCE commands below:
BALANCE DATAis used to migrate data from old machines to new machinesBALANCE LEADERonly changes the distribution of leader partition to balance the work load without moving data
Table of Contents
Intro to the balance mechanism
Cluster data migration
Step 1: Prerequisites
Step 1.1 Show the current cluster status
Step 1.2 Create graph spaces
Step 2 Add new hosts
Step 3 Data migration
Step 4 If stop data balance halfway, ...
Step 5 Data migration is done
Step 6 Next, balance leader
Batch scale in
Conclution
Intro to the balance mechanism
In NebulaGraph balance means to balance both the raft leader and partition data. But the balance does not change the numbers of leaders or partitions.
When you add a new machine with Nebula service, the (new) storage will automatically register to the Meta service. Meta calculates an equally partition distribution, and then uses remove partition and add partition to make those partitions distributed evenly. The corresponding command is BALANCE DATA. Usually, the data migration is a time-consuming process.
However, BALANCE DATA only changes the replica distribution among the machines. But the leaders (corresponding work load) will not be changed. Next, you need to use the BALANCE LEADER command to achieve load balance. This process is also implemented through the meta service.
Cluster data migration
The following example will show how to expand the cluster from three instances to eight instances.
Step 1 Prerequisites
Suppose you've already start a cluster with three replicas.
Step 1.1 Show the current cluster status
Show the current status with command SHOW HOSTS:
Explanations on the returned results:
IP and Port are the storage instance. The cluster has three storaged instances (192.168.8.210:34600, 192.168.8.210:34700, 192.168.8.210:34500) without any data.
Status shows the state of each instance. There are two kinds of states, i.e. online/offline. When a host crashed, metad will turn it to offline after its heart beat timed out. The default heart beat threshold is 10 minutes (You can find parameter
expired_threshold_secmeta's config file).Leader count shows the number of raft leader of the instance served.
Leader distribution shows how the leader distributed in each graph space. For now there are no spaces created. (You can regard space as an independent name space -- similar to the Database in MySQL.)
Partition distribution shows the partition number of different spaces.
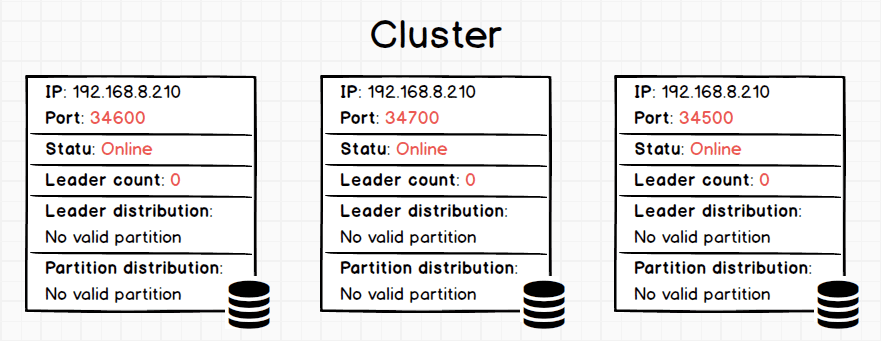
We can see there is no data in the Leader distribution and Partition distribution for the time.
Step 1.2 Create a graph space
Create a graph space named **test** with 100 partition and 3 replicas.
After a few seconds, run the command SHOW HOSTSagain:
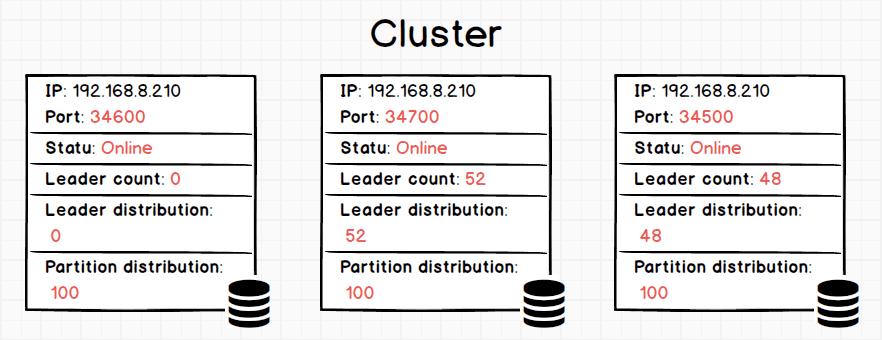
After we created the space test with 100 _partitio_ns and 3 replicas, the host192.168.8.210:34600 serves NO leader, while 192.168.8.210:34700 serves 52 leaders and 192.168.8.210 serves 48 leaders。The leaders are not equally distributed.
Step 2 Add five new instances
Now, let's add five new instances into the cluster.
Again, show the new status using statement SHOW HOSTS. You can see there are already eight instances in serving. But no partition is running on the new instances.
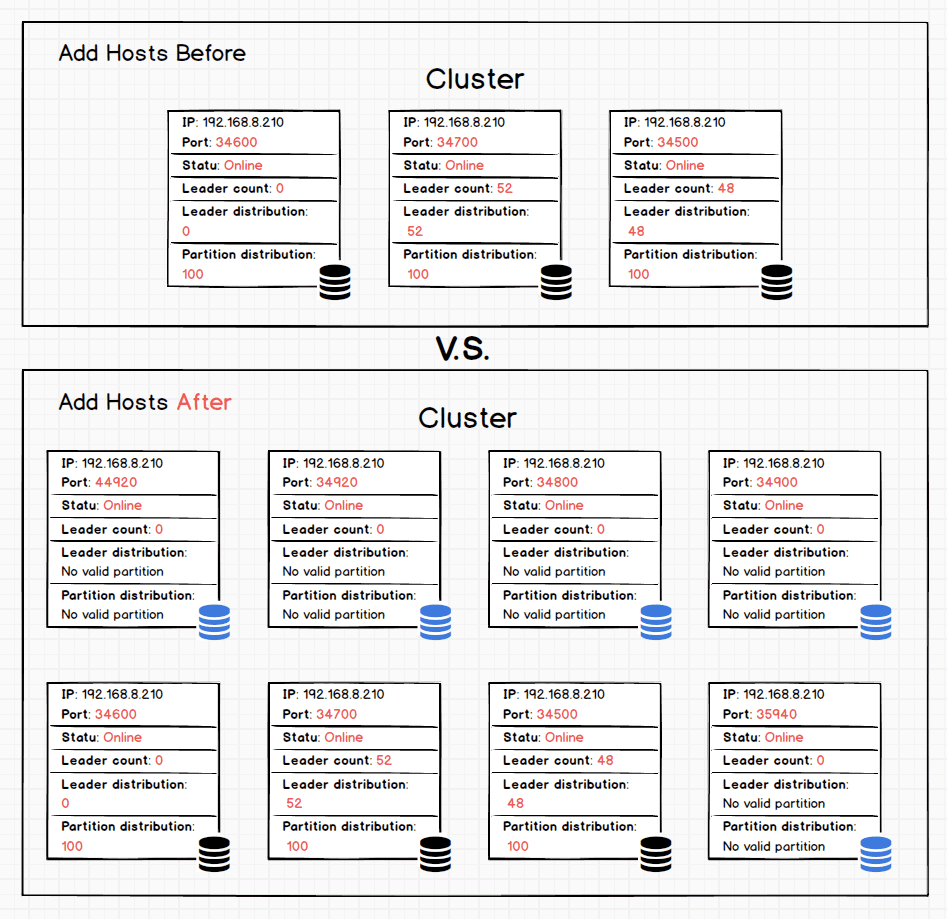
In the above picture, the five blue icons are the newly added ones. However, since we just add them, they serve no partitions.
Step 3 Data migration
Run command BALANCE DATA:
This command will generate a new plan and start a migration process if the partitions are not equally distributed. For a balanced cluster, re-run BALANCE DATA will not cause any new operations.
You can check the running progress of the plan by command BALANCE DATA $id.
Explanations on the returned results:
The first column is a specific task. Take 1570761786, 1:88, 192.168.8.210:34700->192.168.8.210:35940 for example
1570761786 is the balance ID
1:88, 1 is the spaceId (i.e., space
test), 88 is the partition id which is now being moved192.168.8.210:34700->192.168.8.210:3594, moving data from the source instance to the destination instance. The useless data on the source instance will be garbage collected after the migration is finished.
The second column shows the state (result) of the task, there are four states:
Succeeded
Failed
In progress
Invalid
The last row is the summary of the tasks. Some partitions are yet to be migrated.
Step 4 If stop data balance halfway
BALANCE DATA STOP command will stop the running plan and return this plan ID. If there is no running balance plan, an error is thrown.
Since a balance plan includes several balance (sub)tasks,
BALANCE DATA STOPdoesn't stop the running tasks, but rather cancel the subsequent tasks. The running tasks will continue until the executions are completed.
You can run BALANCE DATA $id to show the status of a stopped balance plan.
After all the running (sub)tasks are completed, you can re-run the BALANCE DATA command again to resume the previous balance plan (if applicable). If there are failed tasks in the stopped plan, the plan will retry. Otherwise, if all the tasks are succeed (and e.g., a new machine is added the cluster), a new balance plan will be created and executed.
Step 5 Data Migration is Done
In some cases, the data migration will take hours or even days. During the migration, NebulaGraph online services are not affected. Once migration is done, the progress will show 100%. You can retry BALANCE DATA to fix those failed tasks. If it can't be fixed after several attempts, please contact us at GitHub.
Finally, use the SHOW HOSTS to check the final partition distribution.
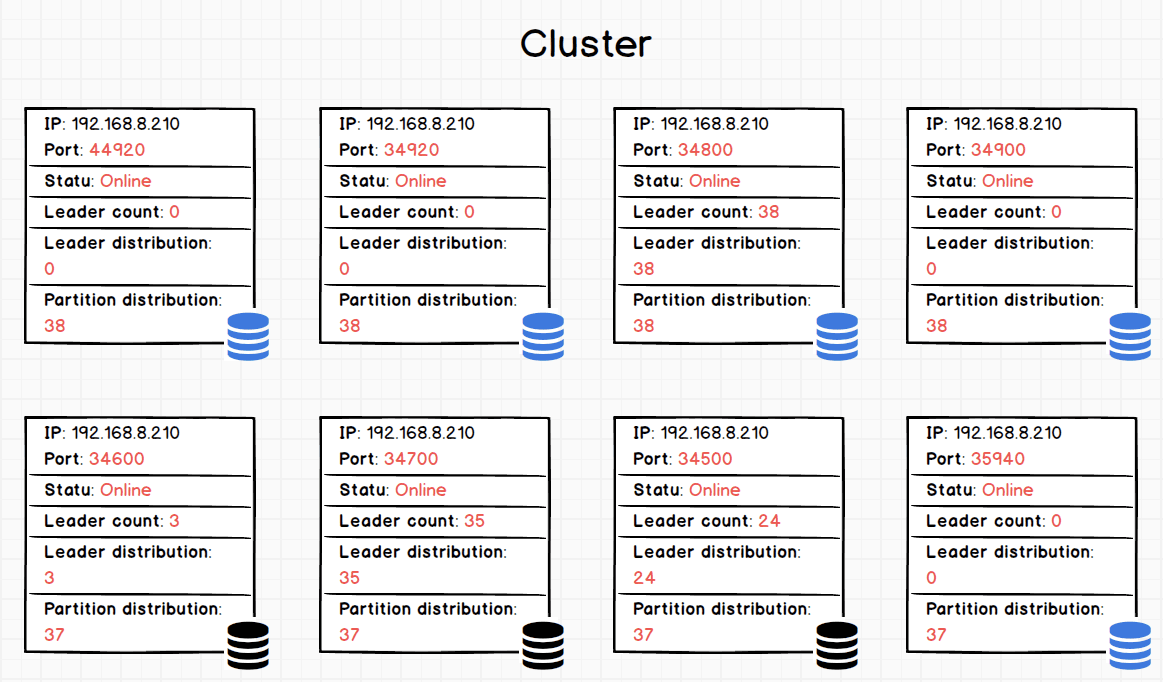
As you can tell from the Partition distribution column, The numbers are close to each other (37 or 38 for an instance), and total partition number is 300. But ...
Step 6 Balance leader
Statement BALANCE DATA only migrates partitions (with the data). But the leader distribution remains unbalanced, which means old hosts are overloaded-working, while the new ones are not fully used. We can re-distribute raft leader using the command BALANCE LEADER.
Seconds later, show the results using the statement SHOW HOSTS.
According to the Leader distribution column, the RAFT leaders are distributed evenly over all the hosts in the cluster.
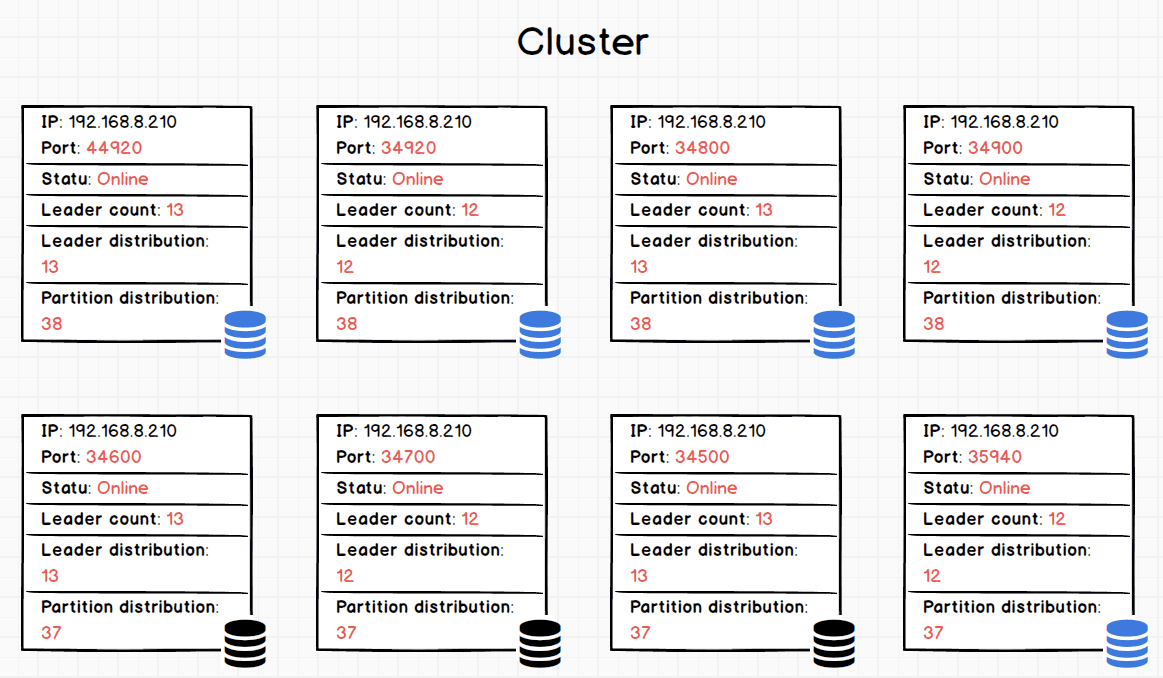
As the above picture indicates, when BALANCE LEADER runs successfully, the number of Leader distribution on the newly added (the blue icon) and the original instances (the black icon) are close to each other (12 or 13 for an instance). Besides, as there are no change to the Partition distribution number, it indicates that balance leader only involves the re-distribution of leaders from instances.
Batch Scale in
NebulaGraph also supports to go offline a host (and scale in the cluster) during service. The command is BALANCE DATA REMOVE $host_list.
For example, command BALANCE DATA REMOVE 192.168.0.1:50000,192.168.0.2:50000 removes two hosts, i.e. 192.168.0.1:50000 and 192.168.0.2:50000, from the cluster.
If replica number cannot meet the quorum requirement after the remove (e.g., remote two machines from a three machine cluster), NebulaGraph will reject the request and return an error code.
Conclusion
In this post, we showed how to balance data and balance work load on a raft-cluster. If you have any questions, please leave your comment. Finally we tak a glance of the data migration process of instance 192.168.8.210:34600.
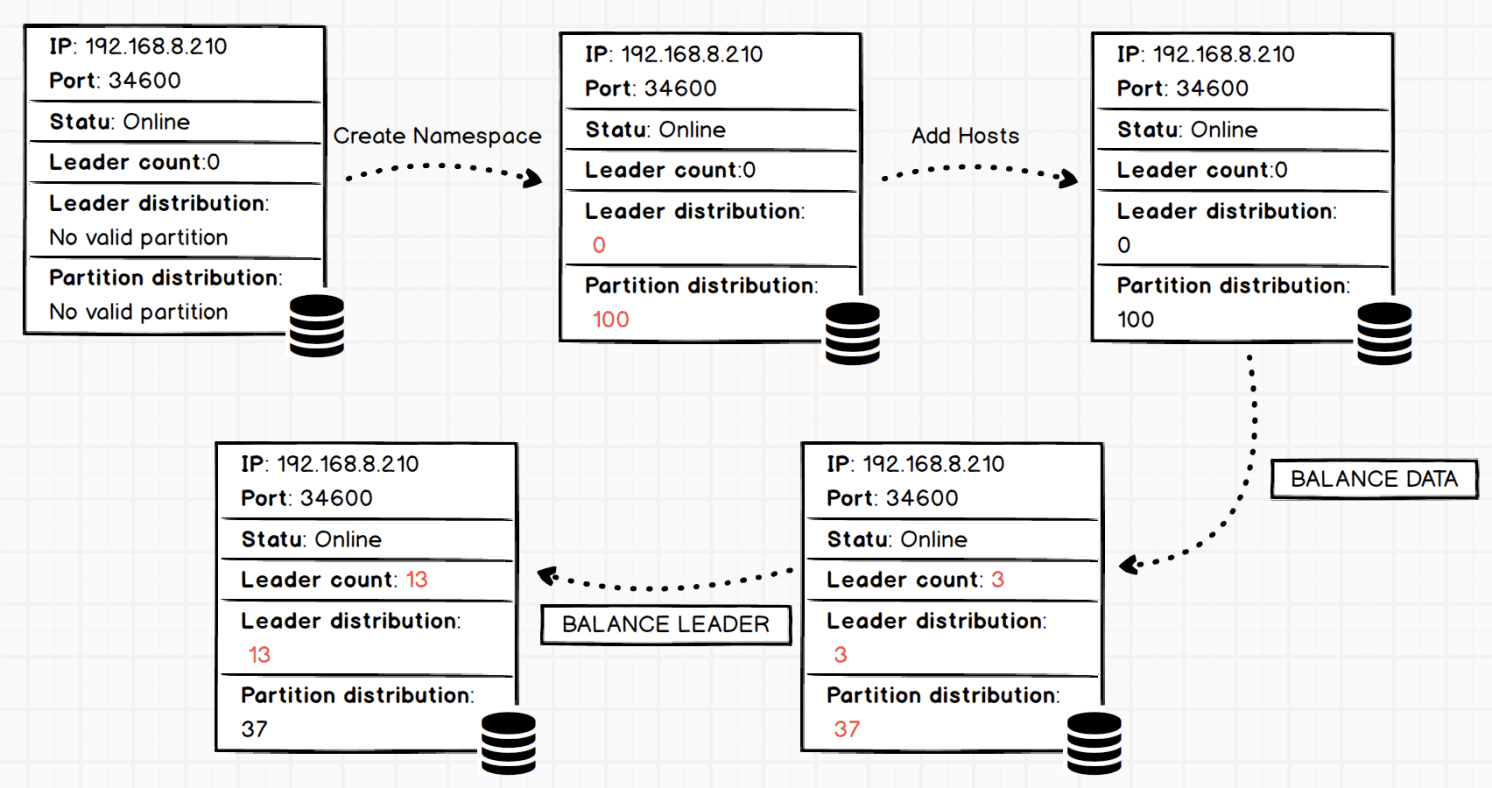
The red number indicates a change has happened after a command is executed.
Appendix
This is the GitHub Repo for NebulaGraph. Welcome to try nebula. IF you have any problems please send us an issue.
