
LLMTech-talkArchitecture
When AI Meets Graph Databases: Innovating with Multimodal Data Fusion (Part I)
Data Challenges in the AI Era
As intelligence transforms industries, data is exploding in volume and variety. Banks generate structured transactions, unstructured customer call recordings, and semi-structured JSON profiles. Hospitals manage free-text medical notes, numerical lab results, and diagnostic images. This flood of multi-source, heterogeneous data is no longer an exception—it’s the norm.
Legacy data systems, built for siloed, single-format processing, can’t keep up. They handle one data type at a time, missing the rich connections between them. But modern AI demands more: it needs holistic, context-rich insights drawn from all available data dimensions.
The challenge has shifted. It’s no longer just about storage—it’s about understanding. In the AI era, systems must mimic human cognition, linking disparate data points across modalities to form meaningful networks.
At present, the integration of multi-source heterogeneous data has become an inevitable trend, and Graph Database is one of the key technologies to solve this problem.
Why Do We Need Graph Databases?
The Limits of Traditional Data Approaches
Traditional data processing methods are struggling to keep up in today’s complex landscape. Early storage models created fragmented, isolated “data silos” with little to no connection between them—making it nearly impossible to see the full picture or unlock the true value hidden in the data.
Taking enterprise customer management as an example, a customer’s profile might live in one table, purchase history in another, and service interactions in yet another. To understand their full journey, you need cross-table joins. But as data grows, these queries become slow and unwieldy with latency jumps from milliseconds to minutes. Worse, mismatched fields during joins can introduce errors, leading to inaccurate insights and flawed business decisions.
The result? Slow, inefficient analytics, overlooked relationships, and a widening disconnect between raw data and actionable insights.
New Demands in the AI Era: Semantic Understanding and Multimodal Fusion
Traditional databases have inherent shortcomings when dealing with multimodal data. Complex implicit associations exist between multimodal data. However, the two-dimensional table structure of traditional databases cannot intuitively express such associations, making the fusion analysis of multimodal data difficult to achieve. AI’s demand for deep semantic understanding further highlights the shortcomings of traditional databases in handling complex and nonlinear relationships.
From Multimodal Data to Relationships Analytics in One Step
To solve the data connectivity challenge, graph databases reframe relationships intuitively: disparate data points become “nodes”, and their logical connections are explicitly modeled as “edges”. This structure enables “one-click” data association—no complex joins required.
Graph databases seamlessly integrate structured and unstructured data into a unified model. For instance, when analyzing how a product’s visual features relate to user sentiment, an “image node” can be directly linked to a “comment text node” via an edge. By combining AI-driven image and text analysis, these connections reveal hidden patterns between visuals and emotions—enabling deeper semantic understanding and powerful cross-modal analytics in the AI era.
How Do Graph Databases Empower Intelligent Data Foundations?
The data intelligence foundation is the core infrastructure for enterprises to achieve intelligent transformation, aiming to integrate multi-source heterogeneous data and provide unified, efficient data support for intelligent applications. Its construction follows a four-step framework: “content analysis, semantic alignment, domain modeling, and relationship map.” In this process, graph databases—natively designed to handle entities and relationships—play a critical role at every stage, serving as the cornerstone for multimodal data fusion and value extraction.
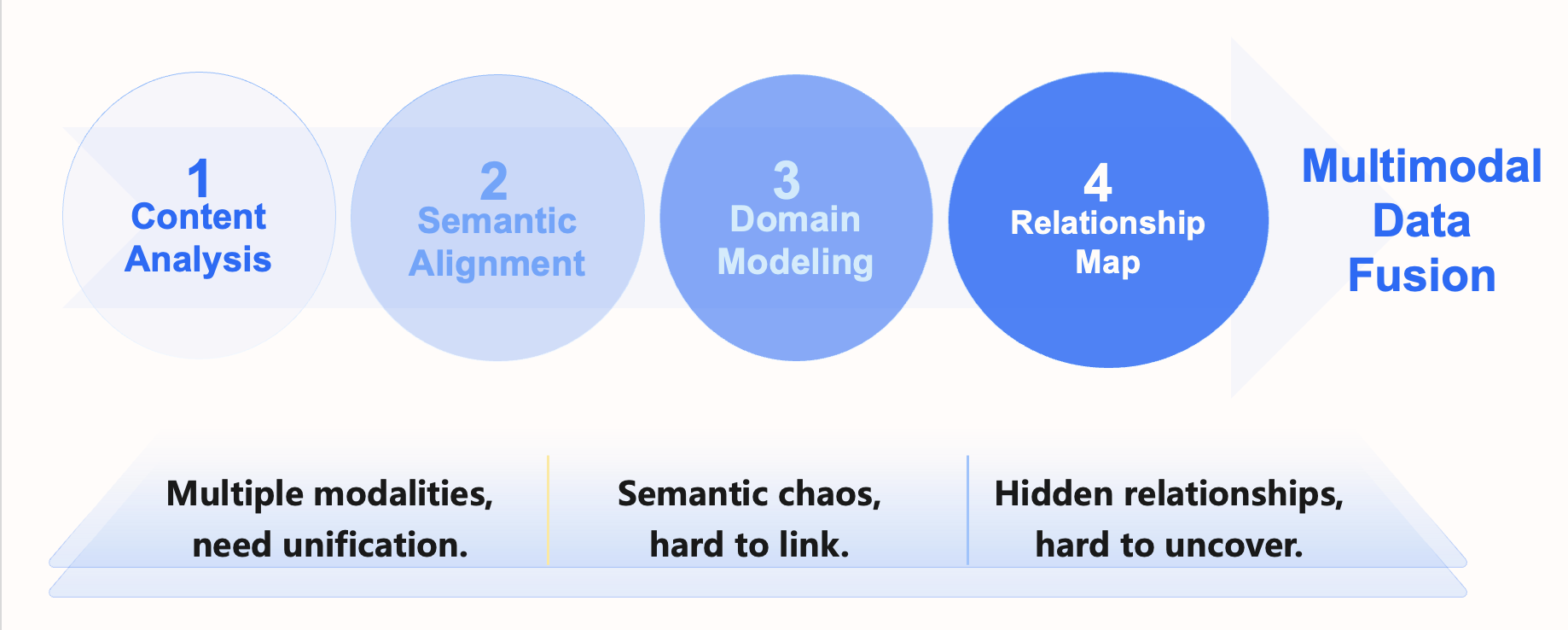
Content Quarks: Turning Raw Data into Structured Building Blocks
Content analysis kicks off the data intelligence foundation. It’s all about unpacking massive, messy raw data—text, images, audio, documents—and extracting the essentials: entities, attributes, and relationships. Think of it as breaking data down into tiny, atomic units we call “content quarks”.
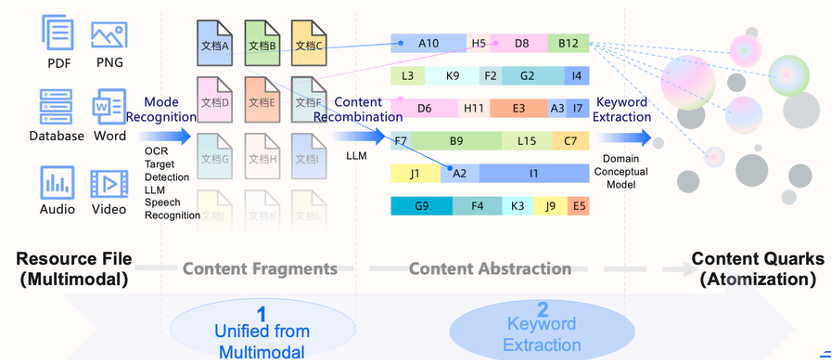
Advanced tools make this possible: OCR reads text in images, speech recognition converts audio to text, and LLM parse meaning from documents. Together, they transform unstructured data into clean, structured fragments.
By defining entity and relationship types upfront, graph databases provide a clear blueprint for extraction. For example, when processing payment records, a pre-built schema can guide the system to spot “User ID”, “Merchant Code”, or actions like “transfers to” with precision. This not only reduces errors but ensures consistency—setting the stage for smarter, more reliable insights down the line.
Semantic Alignment: Breaking Down “Data Silos” and Building a Unified Semantic Space
The goal of semantic alignment is to map data from different systems and with different naming conventions into a unified semantic space, thereby achieving seamless cross-source data connection and interoperability.
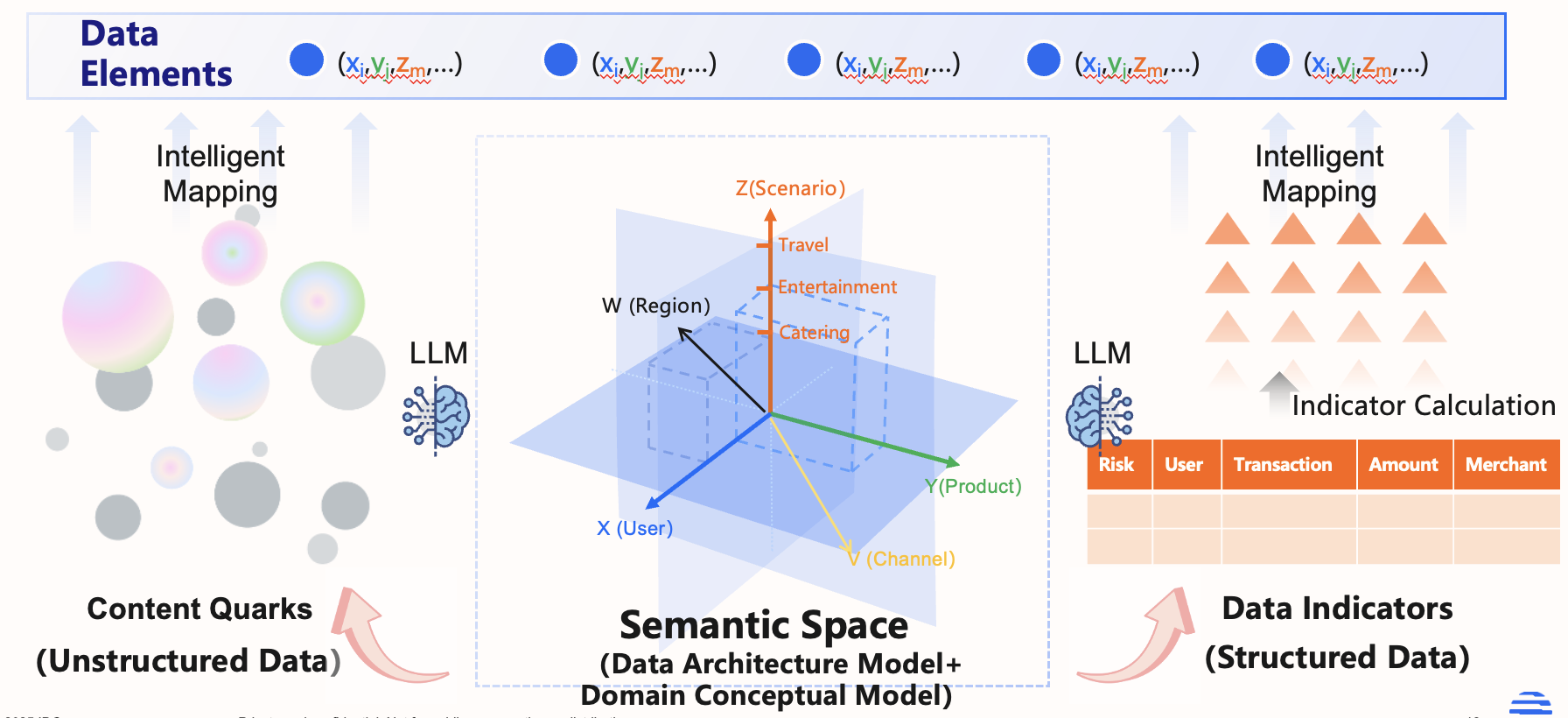
This process combines the power of large language models (LLMs) for semantic understanding, data lineage analysis, and business-specific rules to identify synonyms across systems. For instance, “buyer ID” in an e-commerce platform and “account holder number” in a bank system can be recognized as the same core concept: a “user unique identifier.”
Graph databases are a natural fit for this task. Using their native node-edge structure, they can merge different names for the same real-world entity into a single, unified node. Attributes on that node preserve the original labels from each source—like a “User X” node tagged with Customer ID: 123 and User Number: 456.
This approach allows systems to automatically recognize that different names refer to the same entity—effectively breaking down long-standing data silos and paving the way for powerful, cross-scenario analytics.
Domain Modeling: Flexible Data Structures for Every Use Case
Different business scenarios demand different data perspectives. Risk control focuses on user networks, suspicious transactions, and blacklisted merchants, while marketing looks at user preferences, behaviors, and campaign engagement. Domain modeling tailors the data structure to these specific needs by defining relevant concepts and business rules.
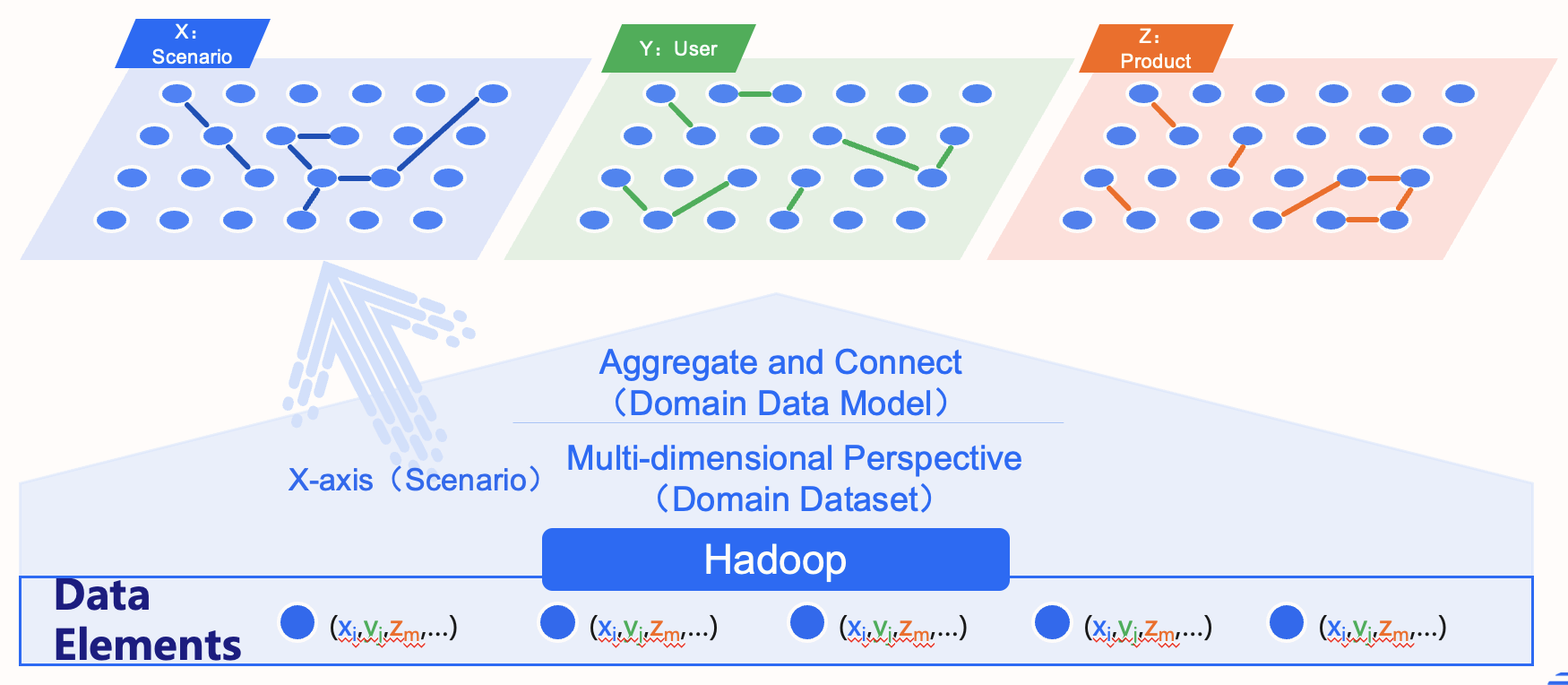
Here, graph databases act like a “customizable shelf”—flexible and easy to rearrange. Instead of rigid table schemas, they represent core ideas as nodes and connections as edges. This makes it simple to model complex relationships, like linking “blacklisted merchants” to “abnormal transactions” in fraud detection.
Best of all, the model can evolve with the business. Need to add “logistics information”? Just introduce a new node and connect it—no schema overhaul required. This agility makes graph databases ideal for building scalable, future-proof data models.
Relationship Map: Connecting the Dots at Scale
The relationship map is the culmination of the four-step data intelligence framework—bringing together all entities and connections uncovered during content analysis, semantic alignment, and domain modeling. It forms a unified, global graph that integrates multimodal data into a single, coherent network, enabling deep data fusion and efficient querying.
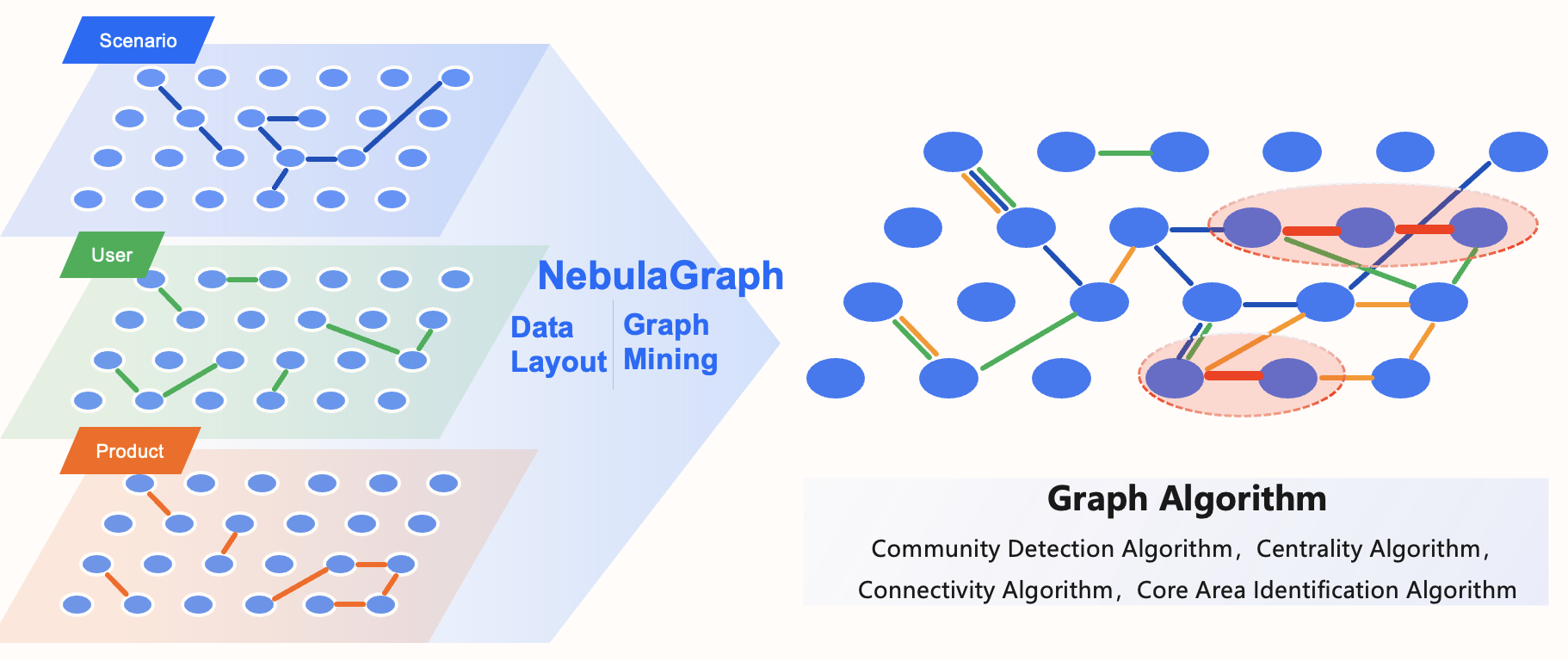
This integrated graph consolidates fragmented data into one connected space. Powered by a robust graph computing engine, it uncovers hidden patterns and complex relationships that traditional systems miss.
The graph database becomes the central “hub” for storage and computation. It efficiently handles billions of nodes and edges while enabling fast, multi-hop traversals and complex pattern searches. For example, in fraud detection, querying “User A” can instantly reveal their transactions, linked merchants, triggered risk rules, and even indirect connections to known bad actors—like tracing a detective’s case map in real time.
With everything interconnected, the graph turns scattered data into actionable intelligence, unlocking the full value of enterprise multimodal data and empowering smarter, faster decisions.
Graph Databases: The Engine of Data Intelligence
Graph databases provide a standardized framework for content extraction, enable a unified semantic layer for data alignment, offer a flexible structure for domain-specific modeling, and serve as a high-performance engine for storing and querying the relationship map.
More than just a database, graph databases represented by NebulaGraph is the core enabler of multimodal, heterogeneous data fusion—turning fragmented information into connected knowledge. By unlocking deep relationships and hidden patterns, graph databases power advanced applications like intelligent analytics, real-time risk detection, and precision marketing, laying a strong, scalable foundation for the intelligence of enterprise.
In the first half, this article delved into the core role of graph databases in addressing the challenges of multimodal and heterogeneous data and detailed how they empower the intelligent data foundation. In the next part, we will further explore application innovation based on this and the exciting potential of integrating graph databases with AI. Stay tuned.



