
LLM
KG-RAG: Bridging the Gap Between Knowledge and Creativity of LLM-based Agents
This blog is written by Diego Sanmartin and originally published on Medium
Large language models (LLMs) have emerged as potential sparks for Artificial General Intelligence (AGI), offering hope for the development of versatile intelligent systems 👀.
➕ Bonus: What are intelligent systems?
As a bonus before delving into the topic of the article, it’s nice to understand the historical context and definitions of intelligent systems. The essence of intelligence has been a constant subject of study over time, reflecting centuries of philosophical inquiry and scientific exploration, as can be seen in the following quotes:
Denis Diderot (1746): “If they find a parrot who could answer to everything, I would claim it to be an intelligent being without hesitation.” 🐦
Alan Turing (1950): “If a machine can engage in a conversation with a human without being detected as a machine, it has demonstrated human intelligence.”
Now, let’s go into the fun part and explore the concept of current AI Agents.
What is an AI Agent? 🤖
An AI Agent can be defined as an artificial entity that is capable of sensing its environment, making decisions, and executing actions. This concept brings us back to the fundamental idea of the robot’s sense-plan-act loop, which allows robots to interact with their environment. Following this definition, when we break down an AI Agent into its elemental components, we can fundamentally decompose it into three core elements: perception, brain, and action.
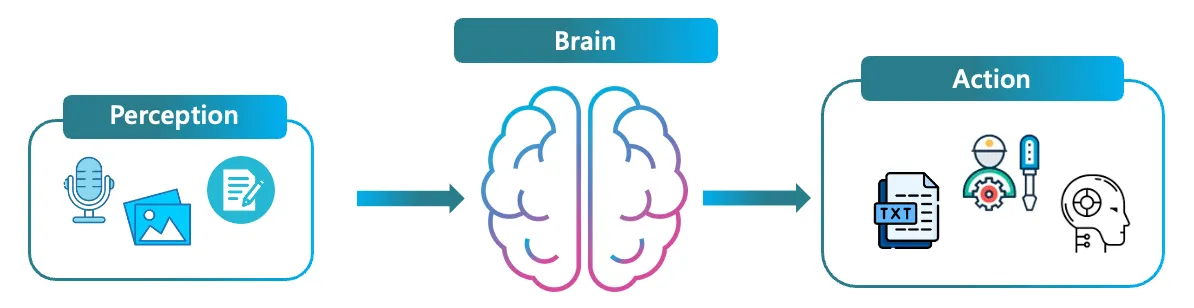 Core components of an AI Agent: Perception, Brain, and Action.
Core components of an AI Agent: Perception, Brain, and Action.
Recent advancements in multimodality and tool execution have notably enhanced both the perception and action components. Today our focus will be directed towards the brain component.
LLM-based Agents 📈
In the diagram below, the brain within the agent is responsible for making decisions, planning, and reasoning, all while interacting with the storage of memory and knowledge. Current agents leverage LLMs for this, given their efficiency in handling reasoning and decision-making through emerging prompt engineering techniques like Chain of Thought (CoT) and ReAct (Reason and Act).
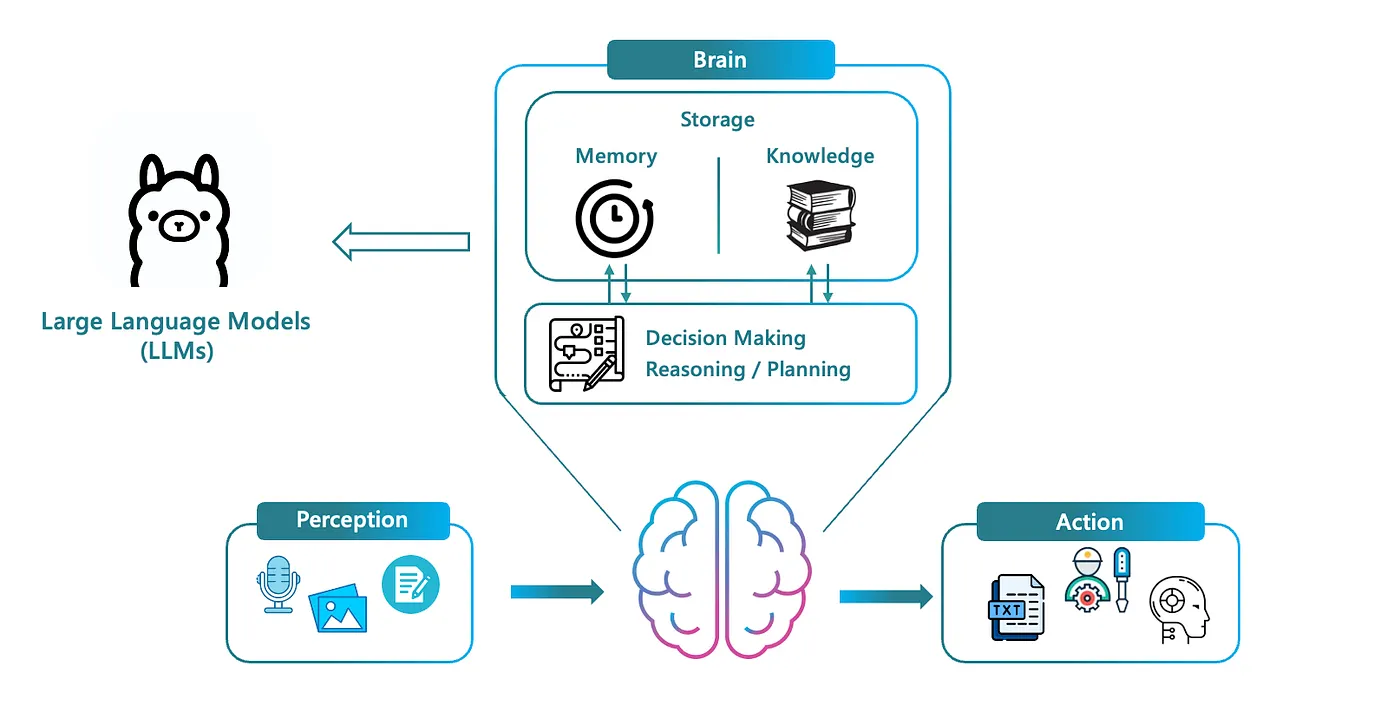 Brain decomposition of an LLM-Based Agent
Brain decomposition of an LLM-Based Agent
However, despite their capabilities on these tasks, LLMs confront several challenges that make them unreliable for knowledge-intensive tasks. This is due to several factors, including:
- Their disposition to generate factually incorrect information — often called hallucinations.
- Limitations related to processing long context lengths effectively, without loosing important details in the middle.
- The phenomenon of catastrophic forgetting, where the model forgets previously learned information as it learns new information.
As AI Agents start being implemented in real-life applications, there is a growing demand for them to be reliable and accurate agents. Hence, figuring out how to bridge the gap between the creative potential of LLMs and the reliable knowledge required in LLM-based agents remains a formidable challenge.
This post delves into the KG-RAG (Knowledge Graph-Retrieval Augmented Generation) framework, also known as Graph RAG, designed explicitly to confront some of the most persistent challenges encountered in LLMs. Preliminary experiments from this framework, demonstrate notable improvements in the reduction of hallucinated content and suggest a promising path toward developing intelligent systems adept at handling knowledge-intensive tasks.
What can be done with KG-RAG? 🧠
KG-RAG enhances LLMs by integrating structured Knowledge Graphs (KGs) that store vast amounts of explicit, factual information. This integration reduces the reliance on the latent, often flawed knowledge of LLMs, enabling LLM-based agents with reliable storage of memory and knowledge to mitigate the generation of hallucinated content.
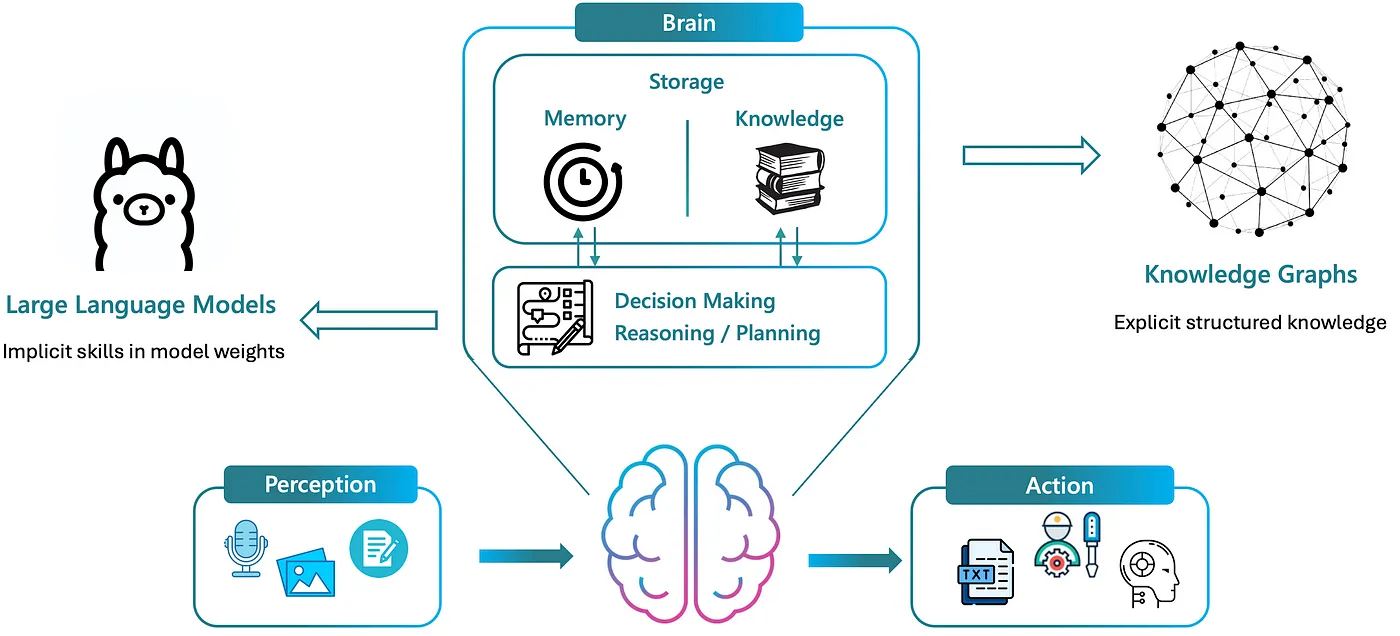 Representation of how the brain integrates LLMs for dynamic reasoning and decision-making, alongside KGs for structured knowledge and memory storage.
Representation of how the brain integrates LLMs for dynamic reasoning and decision-making, alongside KGs for structured knowledge and memory storage.
What is a Knowledge Graph? 🤔
A Knowledge Graph (KG) is a method used to represent and store informational facts. It consists of nodes (or entities) and edges, which represent the relationships between these entities.
For example, in the knowledge graph shown, entities such as “Mona Lisa,” “Da Vinci,” and “Louvre” are connected by relationships like “painted,” “is in,” and “located in.” This visual framework not only helps to depict how different entities are related but also facilitates the retrieval of interconnected information efficiently.

Knowledge graph visualization example A good advantage of using KGs is that they enable us to search for “things, not strings”. They store vast amounts of explicit facts in the form of precise, updatable, and interpretable knowledge triples, which can be represented as (entity)-[relationship]->(entity). Additionally, KGs can actively evolve with the continuous addition of knowledge.
Actually, KGs is what Google uses in Search to provide answers to your questions. As illustrated below, when a user queries “Who is the CEO of Entrepreneur First?” Google uses its Knowledge Graph to fetch and display relevant information. It identifies “Entrepreneur First” as an entity and navigates through the “CEO” relationship to arrive at Alice Bentick and shows how this connection was established in 2011 when she began her tenure as CEO. The KG’s ability to associate Alice Bentick with Entrepreneur First allows Google Search to present a concise and accurate answer to the query.
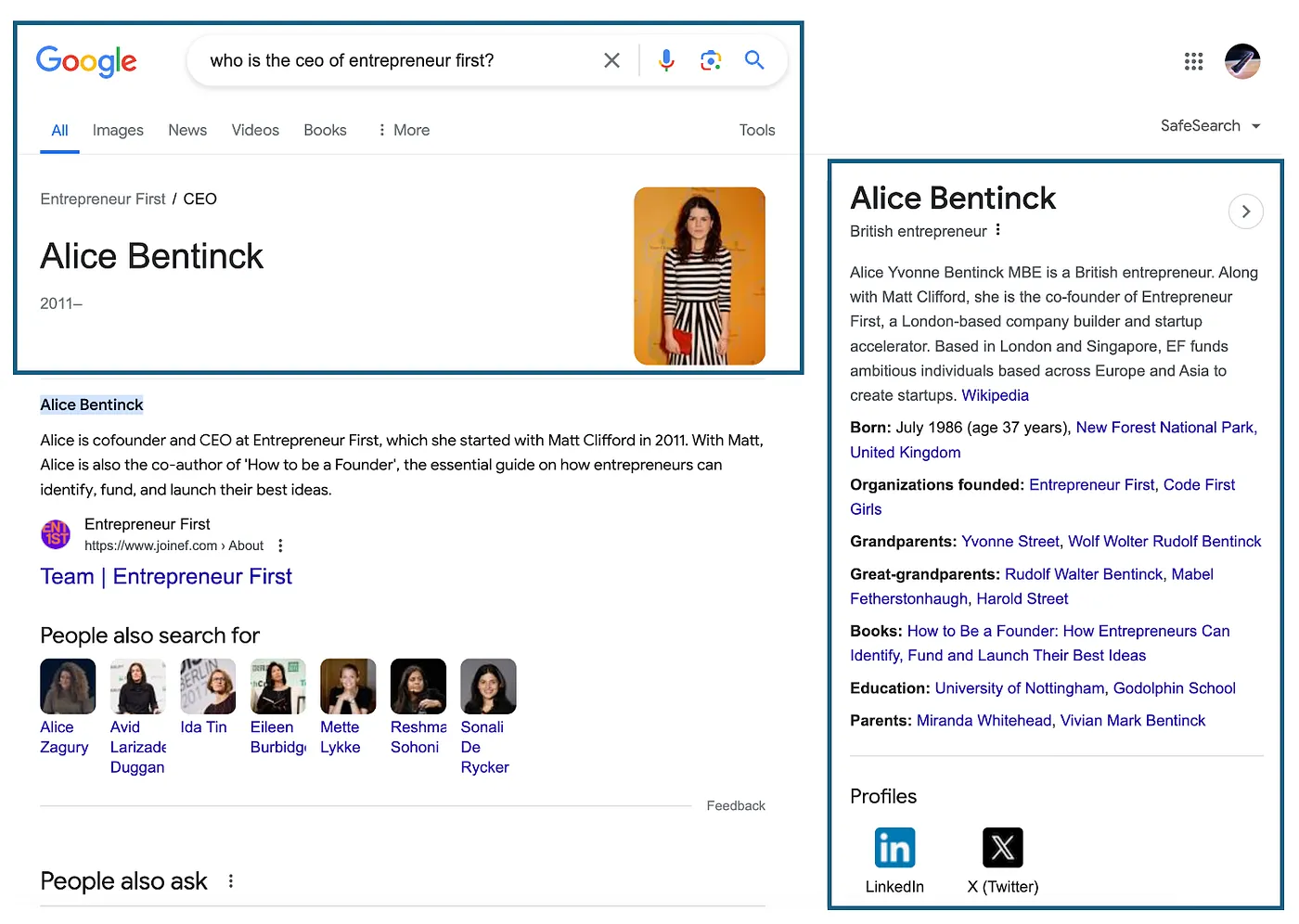
Google search results for “Who is the CEO of Entrepreneur First?”
Additionally, it provides more information that is connected through relationships to the target node (Alice Bentinck) on the right panel.
Motivations behind KG-RAG 💪
The current baseline for the development of AI Agents is creating dense vector representations of chunks of text and retrieving them through a similarity search. This method works well for simple cases.
Example of successful vector retrieval of documents
This method allows AI to quickly find relevant documents based on text similarity, efficiently handling straightforward queries. However, as the volume of similar documents increases, challenges emerge in finding those chunks that contain the exact information needed.
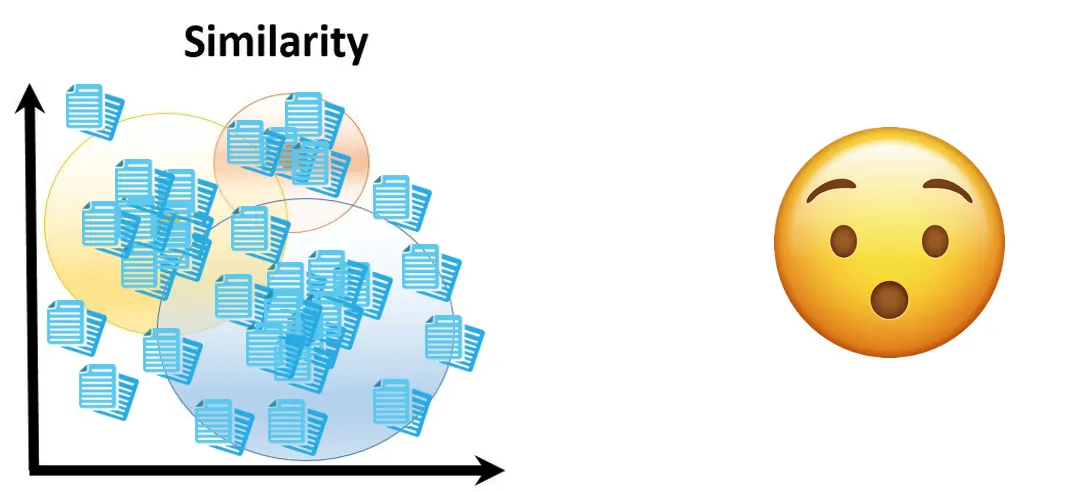 Representation of the scalability issues in vector embeddings based RAG
Representation of the scalability issues in vector embeddings based RAG
These challenges motivate the implementation of structured KGs, enabling the navigation through massive amounts of information in a more efficient and accurate manner.
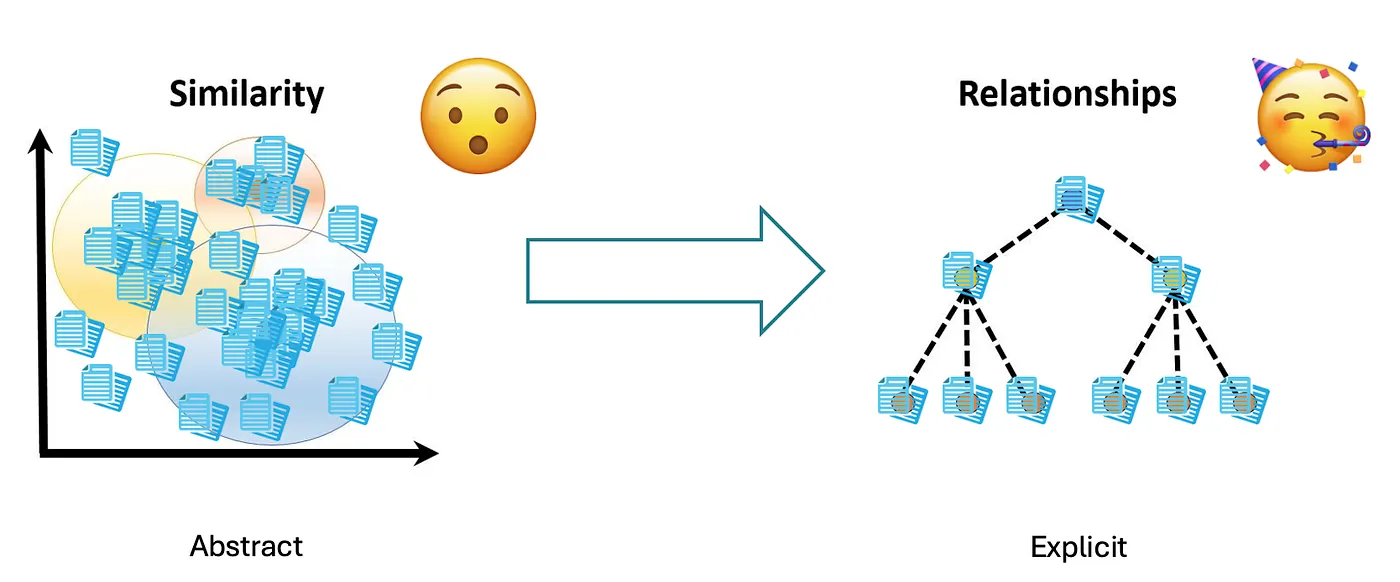
KG-RAG Methodology 🎩
KG-RAG consists of three main stages:
- KG Construction: Converts unstructured text into a structured KG. This step is crucial to maintain the quality of information and can affect later stages if it is not done correctly.
- Retrieval: Carried out through a Chain of Explorations (CoE), a novel retrieval algorithm that employs LLM reasoning to explore nodes and relationships within the KG. It ensures that the retrieval process is both relevant and accurate leveraging the benefits of dense vector representations to locate relevant nodes and relationships within large KGs.
- Response Generation: Generates coherent and contextually appropriate responses.
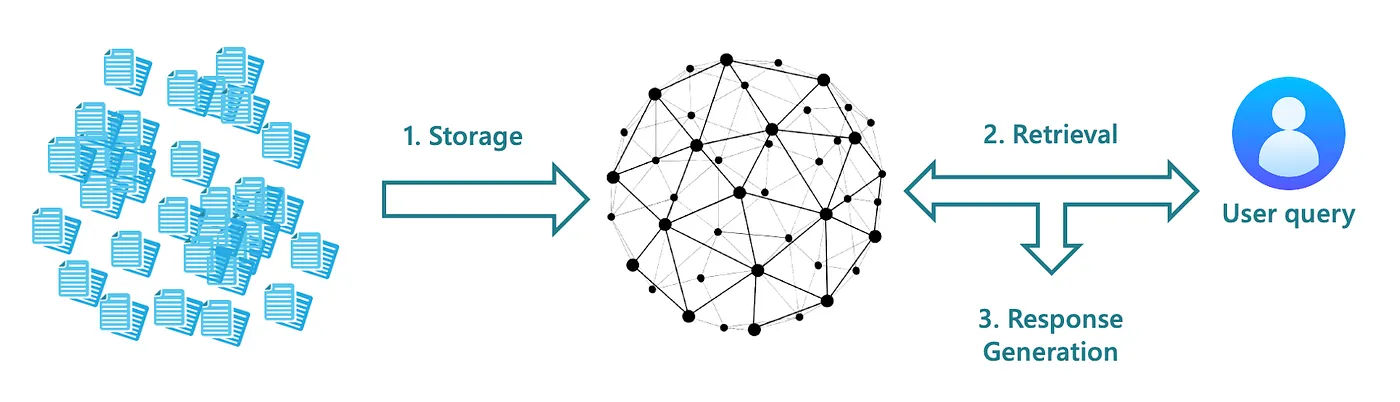 Diagram illustrating the KG-RAG workflow
Diagram illustrating the KG-RAG workflow
Preliminary Results 👀
Here is an example comparison of KG-RAG against the baseline vector RAG approach. This illustrates how KG-RAG effectively handles complex queries by exploring and reasoning through specific relationships to generate responses.
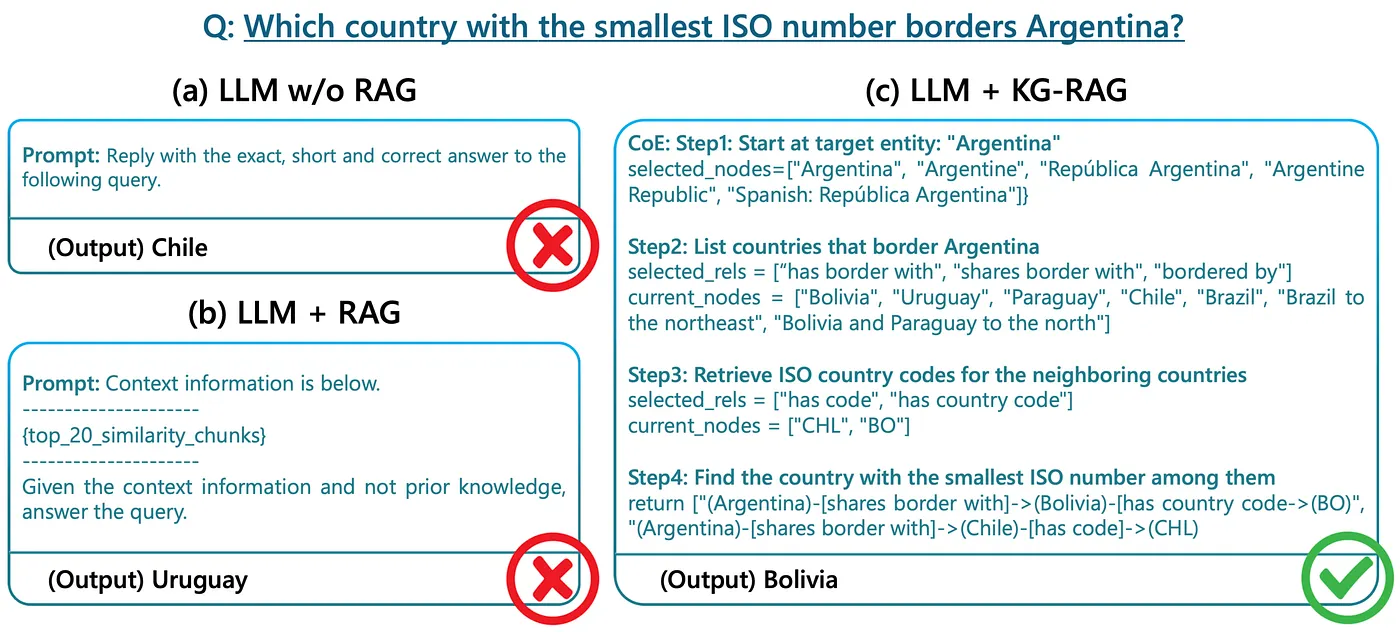 KG-RAG vs Dense Vector RAG vs no RAG on the ComplexWebQuestions dataset
KG-RAG vs Dense Vector RAG vs no RAG on the ComplexWebQuestions dataset
The Future of Intelligent Agents 🔮
The integration of KGs and LLMs through frameworks like KG-RAG suggests a promising path toward developing intelligent systems capable of tackling knowledge-intensive tasks with high reliability. This approach mitigates some of the current limitations in LLM-based Agents and encourages further research and practical applications of this method. There is a significant opportunity to improve the current capabilities of KG Construction by developing curated high-quality datasets specifically tailored for this field.
KG-RAG holds promise as a potential solution to equip LLMs with external, updatable knowledge that is both reliable and efficient. Furthermore, with the continuous advancements in AI hardware accelerators, the reduction in response times (with KG-RAG and reasoning processes happening behind) will make the interactions with these agents feel more natural to humans.
Bonus Analogy 💭
From a perspective of human cognition, the analogy of the “extended mind”, becomes particularly relevant. Just as humans extend their cognitive capabilities using tools such as smartphones and notebooks to offload memory and manage complex tasks, LLM-based agents can similarly benefit from external cognitive extensions to enhance their cognitive capacities.
Closing Note 👋
This medium article is a very short summary of the KG-RAG research paper. If you found this post insightful, delving into the full paper will provide a more comprehensive understanding of our findings and methodologies.



