Architecture
Apr 14, 2021
Communications in a Cluster: About Heartbeat Mechanism
critical27
In the process of using NebulaGraph, users often encounter various problems. To troubleshoot them, we usually recommend running the SHOW HOSTS statement first to view the cluster status. In a sense, the status of a NebulaGraph cluster is determined by a heartbeat mechanism.
This article introduces the heartbeat mechanism through which the servers in a NebulaGraph cluster communicate with each other.
What is Heartbeat?
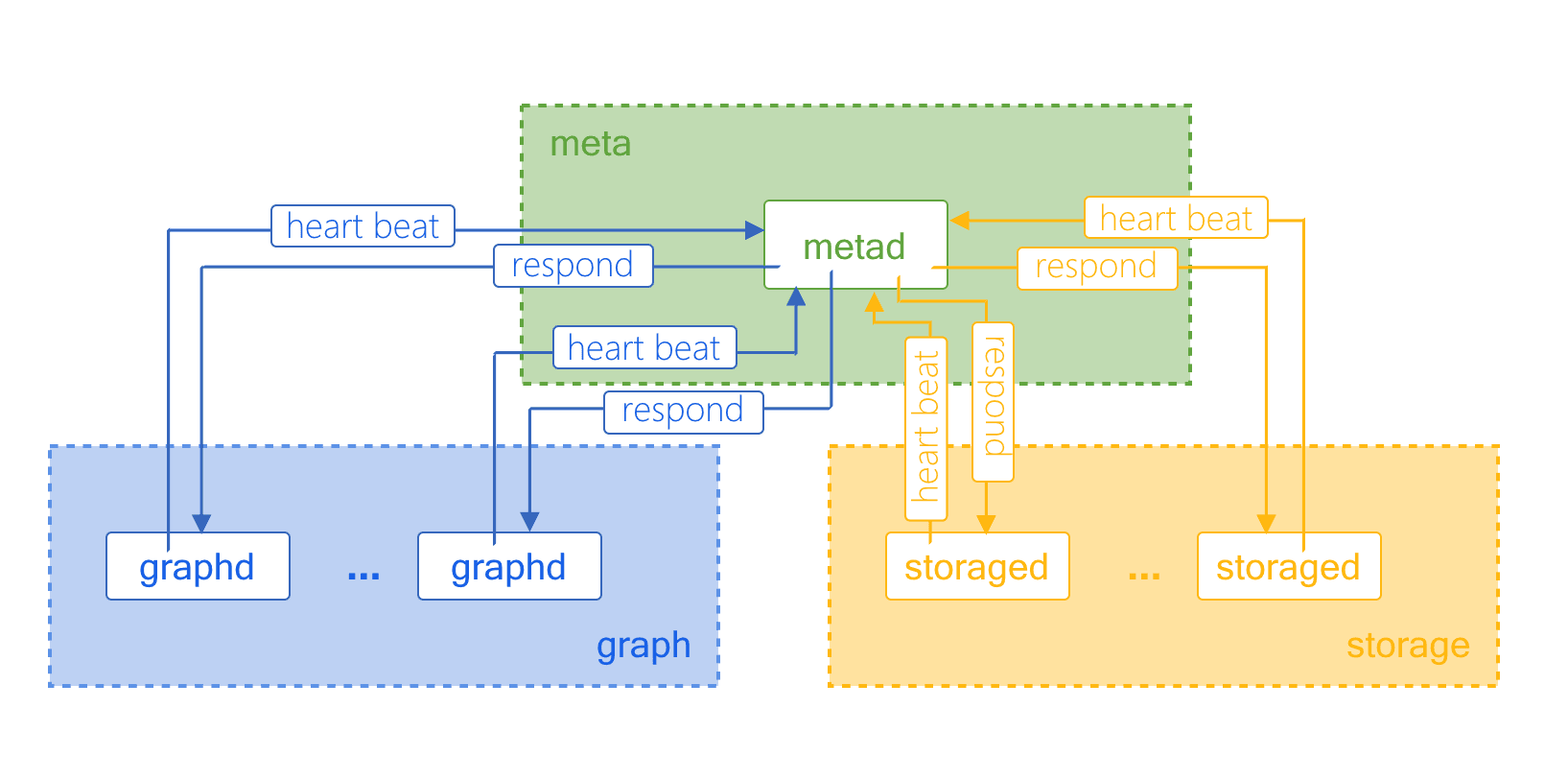
A NebulaGraph cluster contains three types of servers: nebula-graphd servers for querying, nebula-storaged servers for storing business data, and nebula-metad servers for storing metadata. The heartbeats mentioned in this article refer to the heartbeat messages periodically sent by nebula-graphd servers and nebula-storaged servers to nebula-metad servers. With the heartbeats, a cluster can perform the following functions. (The necessary parameter is heartbeat_ interval_ secs.)
The heartbeats used by Raft, often mentioned in NebulaGraph, refer to the heartbeats between the nebula-storaged servers with the same partition, which is different from the heartbeats referred to in this article.
1. Discovering Services
Before starting a NebulaGraph cluster, users must configure the meta_host_addrs parameter in the specified configuration file. When the nebula-graphd servers and the nebula-storaged servers start, they send heartbeat messages to the nebula-metad servers at the specified meta_host_addrs addresses. External access to the nebula-graphd servers and the nebula-storaged servers is not available until they connect to the nebula-metad servers. When the nebula-metad servers receive the heartbeat messages, they store the necessary metadata (see the "Reporting Information of servers" section). From then, users can view the connected nebula-storaged servers by running the SHOW HOSTS statement. For NebulaGraph 2.x, users can list the connected nebula-graphd servers by running the SHOW HOSTS GRAPHstatement.
2. Reporting Information of Cluster Nodes
When heartbeat messages are received, nebula-metad servers collect the IP address, the port number, the server type, the heartbeat time, and other information from the messages and store them for subsequent use. For more information, see the "What Do the Heartbeats do?" section.
In addition, the leader information of nebula-storaged servers is also reported when the leader number is updated. In the result returned for a SHOW HOSTS query, the Leader count and Leader distribution information are from the heartbeat messages.
3. Updating Metadata
The heartbeat response sent by nebula-metad servers to nebula-graphd servers and nebula-storaged servers contain the last_update_time information, which informs the last update time of the metadata. When the information is updated, nebula-graphd servers and nebula-storaged servers will send a heartbeat request to nebula-metad servers for the updated information of the graph space, the schema, and the configurations.
For example, when a new tag is created, before the information of the new tag is received by the nebula-graphd servers and the nebula-storaged servers, users cannot insert vertices, but receive an error like No schema found. However, after the corresponding information is obtained through heartbeat messages and stored in the local cache, users can insert vertices successfully.
What Do the Heartbeats Do?
Results returned for statements such as
SHOW HOSTSandSHOW PARTSare combinations of the information of the heartbeat messages from all the servers that are stored in nebula-metad servers.Operation and maintenance statements such as
BALANCE DATAandBALANCE LEADERneed to retrieve the online nebula-storaged servers in a cluster. The server status is determined by nebula-metad servers according to whether the last heartbeat time is within the threshold range.When users create a graph space by running
CREATE SPACE, nebula-metad servers also need the status of nebula-storaged servers and then distribute the partitions of the graph space across the online nebula-storaged servers.
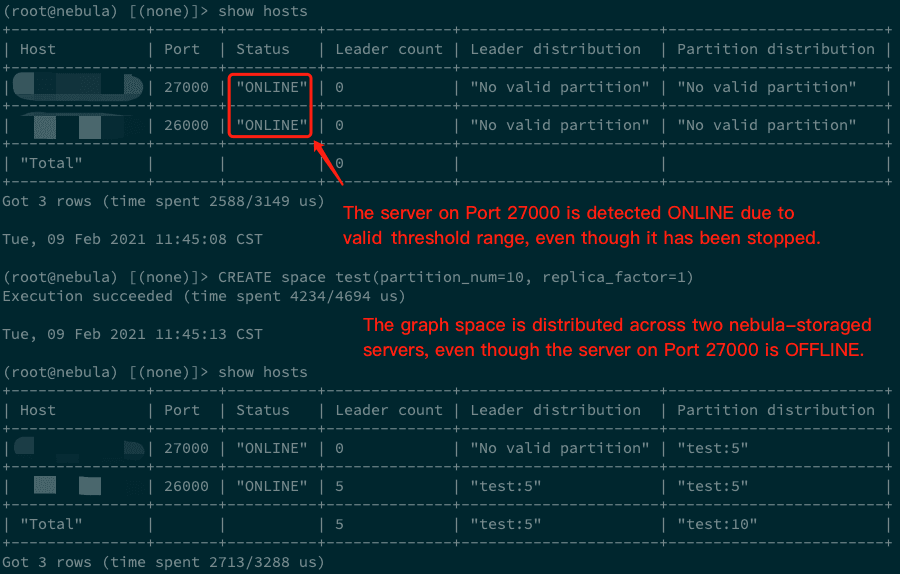
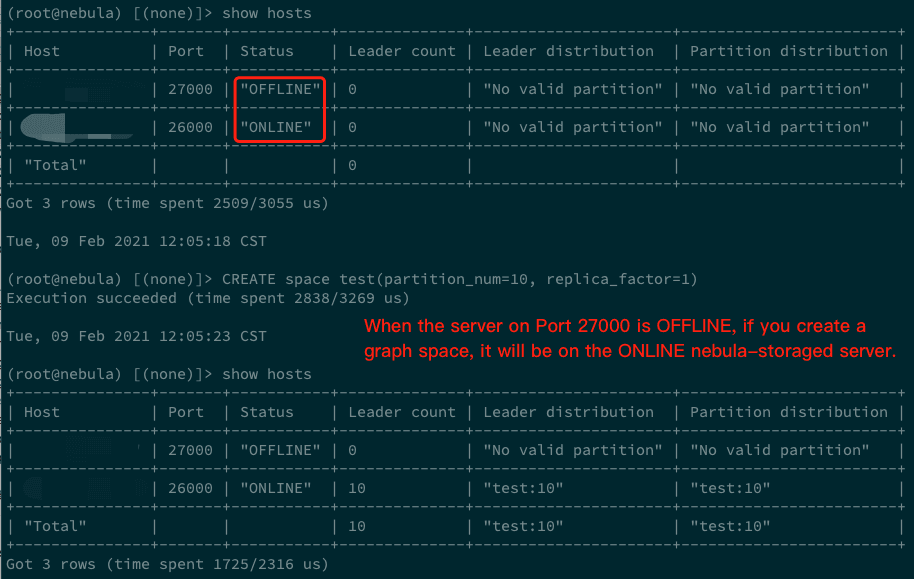
Let's take a common problem as an example: we start a nebula-storaged process, stop it, change the port number, and then start the process again. If the procedure is fast enough, we can see two online nebula-storaged servers by running
SHOW HOSTS. If we immediately create a new graph space by runningCREATE SPACE test(partition_num=10, replica_factor=1), thetestgraph space will be distributed on the two nebula-storaged servers. However, if we create the graph space when only one nebula-storaged server is online and then start the offline server again, the graph space exists in only one nebula-storaged server, that is, the online one during the process of creating thetestgraph space.
Evolution of Heartbeat Mechanism
In 2018-2019, the heartbeat mechanism was not so satisfactory. First, the metadata is obtained from nebula-metad servers regardless of whether the data has been updated. However, the metadata is not updated frequently, so it is a waste of resources to obtain metadata periodically. Second, to add or delete a nebula-storaged server by running statements like ADD HOSTS and DELETE HOSTS, a trustlist-like mechanism is applied. For the servers that are not authenticated, external access to them is not available. This mechanism has its own advantages, but it is not user-friendly enough, which is its biggest disadvantage.
Therefore, since the end of 2019, with the special contributions of @zhangguoqing at JD Digit, we have made some changes to the heartbeat mechanism. After a period of verification, the enhanced heartbeat mechanism is just what you see now.
Extra
Regarding the heartbeat mechanism, you should pay attention to the cluster.id file. It is designed to prevent nebula-storaged servers from communicating with the wrong nebula-metad servers. Here is how it is implemented:
First, when nebula-metad servers start, their hash values are generated based on the configuration of
meta_host_addrsand are stored as KV pairs locally.When nebula-storaged servers start, they will try to obtain the hash values of the corresponding nebula-metad servers from the cluster.id file, and send them in the heartbeat message. If the file does not exist, 0 is used for the first time instead. When heartbeat response are received, the hash values are stored in the cluster.id file and the values will be used all the time.
During the processing of heartbeats, nebula-metad servers compare the local hash values with those in a heartbeat request sent by nebula-storaged servers. If they do not match, the request is rejected. In this case, external access to nebula-storaged servers is not available. This is how the Reject wrong cluster host log is generated.
This is an introduction to the heartbeat mechanism of NebulaGraph. If you are interested, see how it is implemented in the source code: https://github.com/vesoft-inc/nebula-graph.
You Might Also Like

Go From Zero to Graph in Minutes
Spin Up Your NebulaGraph Cluster Instantly!