Community Spotlights
Nov 25, 2022
Hands-on Tutorial for Hive-Data-Import with NebulaGraph Exchange
xrfinbj
This article was written by a NebulaGraph community contributor xrfinbj. It introduces the process and notes of importing data from Hive to NebulaGraph with NebulaGraph Exchange.
Background
The company StoneWise had internal needs of using graph databases and the NebulaGraph database was confirmed to use through technical selection. We still needed to verify the query performance of the NebulaGraph database in real business scenarios. Therefore, we urgently needed to import data to NebulaGraph and validate the performance. We found that the documentation of importing data to NebulaGraph from Hive with Exchange was not very complete, so I decided to record the pitfalls we stepped in this process to avoid detours and traps.
This article was written based on NebulaGraph Documentions: Import data from Hive
Environment
NebulaGraph: nightly
Deployment: Docker on Mac
Hardware:
Disk: SSD
CPU、Memory: 16 G
Data warehouse environment (Local data warehouse on Mac)
Hive 3.1.2
Hadoop 3.2.1
Exchange: https://github.com/vesoft-inc/nebula-java/tree/v1.0/tools/exchange (Compile and generate a JAR package)
Spark:spark-2.4.7-bin-hadoop2.7 (Configure
core-site.xml,hdfs-site.xml,hive-site.xmlin the$HADOOP_HOME/etc/hadoopdirectory, and configurespark-env.shin the$SPARK_HOME/confdirectory.)Scala code runner version 2.13.3 – Copyright 2002-2020, LAMP/EPFL and Lightbend, Inc.
Configuration
NebulaGraph DDL
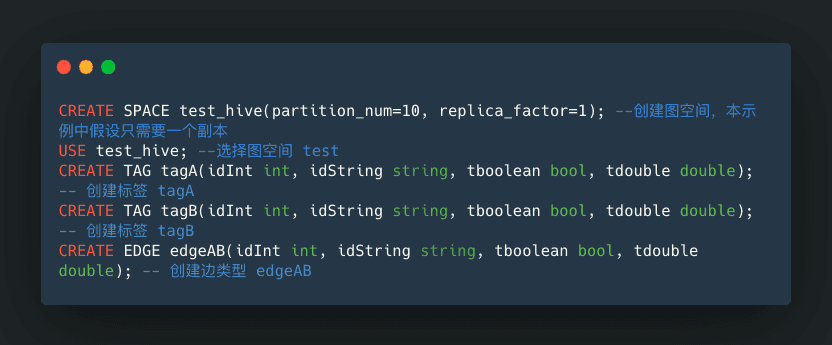
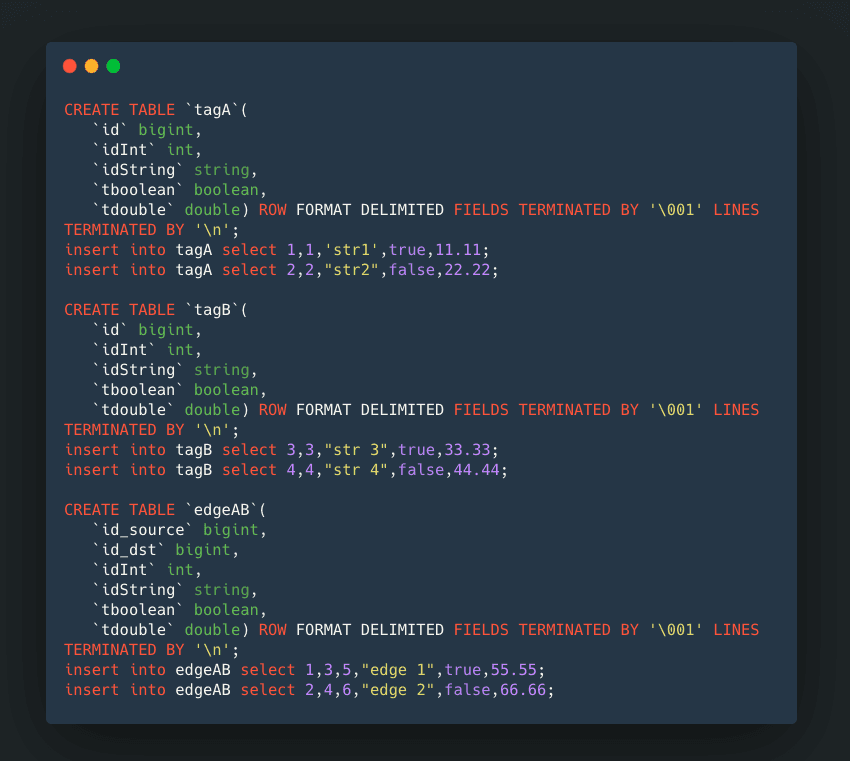
Hive DDL
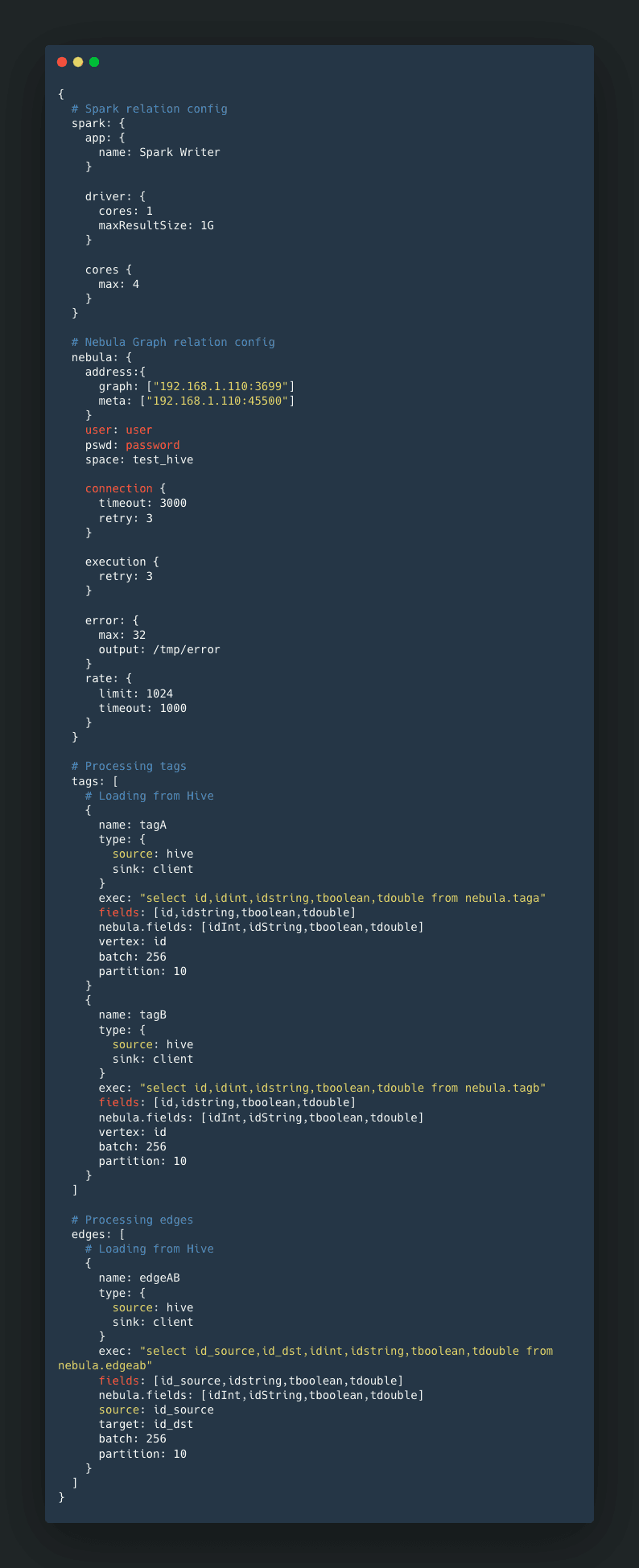
The latest
nebula_application.conffile. Pay attention to these field mappings:exec,fields,nebula.fields,vertex,source, andtarget.
Starting the Import
Make sure that the NebulaGraph service is started.
Make sure that Hive tables and data are ready.
Run
spark-sql clito see if the Hive tables and data are ready to ensure the Spark environment is OK.
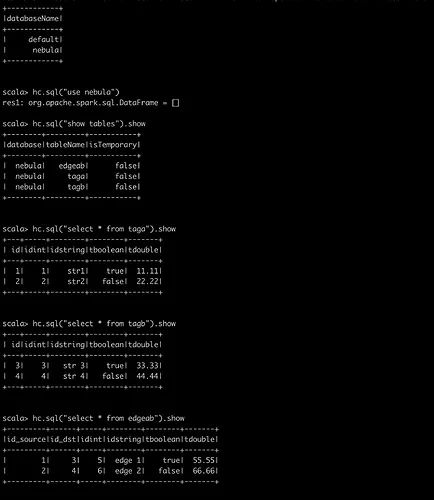
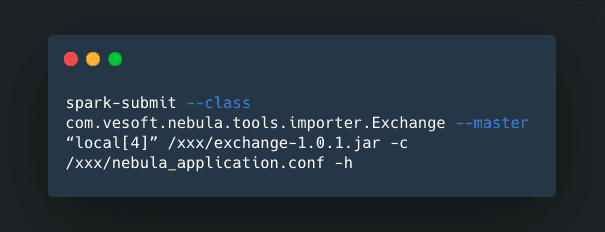
When the configuration is ready, execute Spark commands.
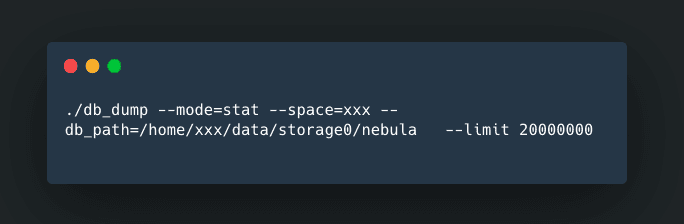
After successful import, you can check the amount of data imported with the db_dump tool.
Pitfalls and Notes
The first pitfall is that the spark-submit command does not add the
-hoption.The tagName in NebulaGraph is case-sensitive. the name in the configuration of tags should be the tag name of NebulaGraph.
The Hive data type
intand NebulaGraphintare not consistent. The Hivebigintcorresponds to the NebulaGraphint.
Other Notes
INSERT operations have better performance than UPDATE because the underlying storage of NebulaGraph is KV Store. Repeated insertions are overwriting the data.
In addition to the information in the documentation, I also read the source code and made posts on the forum.
I have verified the following two scenarios:
Importing data from Hive 2 (Hadoop 2) to NebulaGraph with Spark 2.4
Importing data from Hive 3 (Hadoop 3) to NebulaGraph with Spark 2.4
Note: Exchange does not support Spark 3 yet, and it reports an error after compiling, so it is hard to verify the Spark 3 environment.
There are still some questions.
How to set the parameters
batchandrate.limitin thenebula_application.conffile?The principle of using Exchange to import data from Hive (I've started learning Spark recently.)
Exchange Source Code Debugging
For information about Spark debugging, see https://dzone.com/articles/how-to-attach-a-debugger-to-apache-spark.
Through the Exchange source code learning and debugging, I found that only in conjunction with the source code can I understood the descriptions about importing SST files and the Download and Ingest in the document.
Debugging the source code also helped me find some configuration problems.
Step 1:
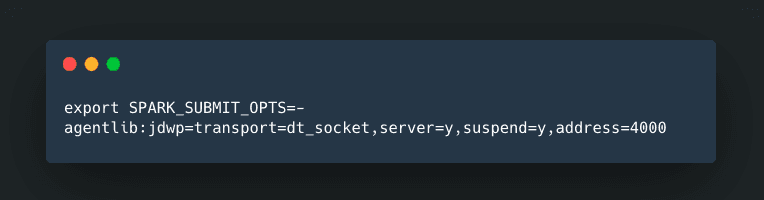
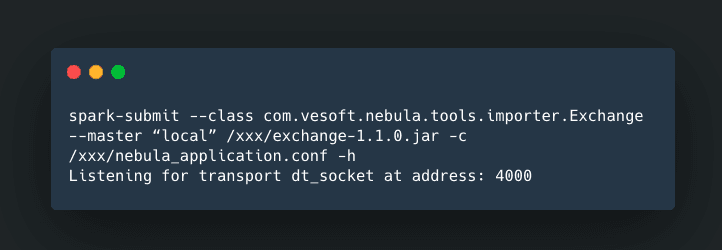
Step 2:
Step 3: IDEA configuration
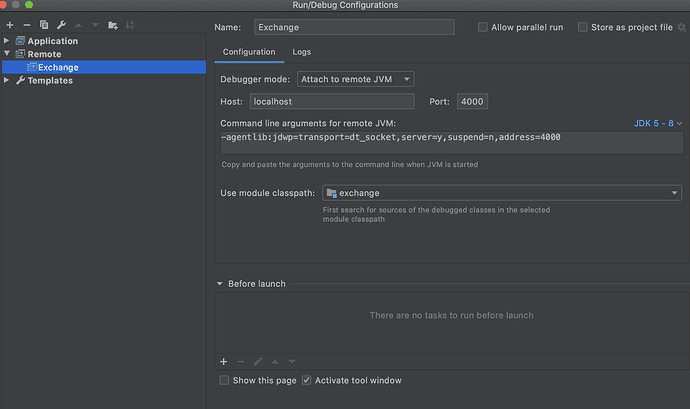
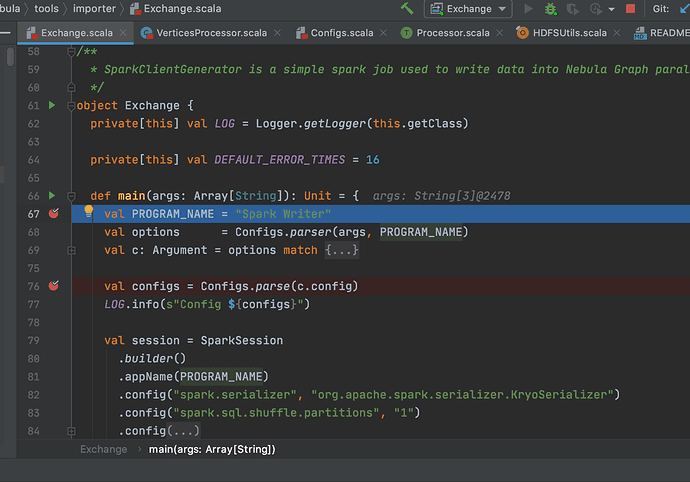
Step 4: Click Debug in IDEA
Suggestions and Gratitude
Thanks to NebulaGraph database, which can solve many practical problems in the business. The problems I met are nothing compared to the problems met by others. The problems encountered in the middle of the process received timely feedback from the community.
Are you passionate about graph databases and graph technology? Join the NebulaGraph Open Source Community to exchange ideas and learn practical skills with experts. Join Slack
NebulaGraph is OPEN SOURCE:https://github.com/vesoft-inc/nebula We highly appreciate every Stargazer, and please let us know if you like NebulaGraph Database.
