Case Studies
Dec 28, 2022
Insurance Fraud Detection with Graph Technology | A Practice of NebulaGraph
Dang
Background
Traditional risk control mainly relies on manual review and empirical judgment. With the rise of digitalization in the past decade, leading companies began to introduce blacklisting systems to locate the risk points missed in the review stage through simple rules and post-facto audits, but this still cannot detect problems in advance. Since 2018, the anti-fraud system has gradually evolved to the stage of "intelligent decision engine" consisting of rule engines, real-time metric calculation, and machine learning technologies.
Insurance Fraud Control Pain Points
The pain points of insurance fraud control are mainly reflected in the following aspects:
Non-exchange information leads to poor risk control: Data of insurance companies and the related industry is non-exchangeable. Even the data between various systems within the same insurance company is unshared. This can lead to asymmetry in business information and false claims, or the use of information asymmetry to increase claim amounts.
Requirements of multi-dimensional computing: Industry fraud diversity, specialization, and grouping will force the anti-fraud system to analyze data from multi-dimensional aspects, while the traditional analysis system based on relational models, dimensional models, or wide table models hardly analyzes data from dozens or even more dimensions.
Accuracy requirements of algorithm recognition: Business model tuning requires more feature data input during the training and serving stages. Generally, there are two methods to input data, one is writing more data, and the other is the supplementing of correlation data. However, if we go with the traditional method, it will be difficult to detect abnormal data with more than 4-hop queries, and the query latency is high.
Underlying Storage Challenges
With the development of the anti-fraud system, the system faces challenges in the aspect of the underlying storage.
The performance of traditional stand-alone databases has bottlenecks in capacity and query for linked data. In addition, business iterations and peaks and valleys have agility requirements for database scalability. Nowadays, most risk control systems use Hadoop ecosystem tools to co-accomplish system goals, and the corresponding development and operation and maintenance costs are high. In terms of real-time data analysis, it's difficult for traditional big data platforms to perform the analysis of multiple sources of data.
Use Scenarios
NebulaGraph is used in many scenarios of insurance fraud detection. The following are 5 typical scenarios.
Scenario 1: Relationship Detection
Customers may skip the family information in the application form. Such uncertain or missing family information are not well determined by the original method. While the graph data structure allows us to find relatives, which is not natively supported by other types of databases.
In addition, the regular form is filled with only immediate relatives, which does not reflect indirect relationships. In NebulaGraph's graph database, more hidden relationships can be discovered through the available data, including social and non-immediate family relationships. It allows for a comprehensive analysis of the family's insurance purchases.
Scenario 2: Fraud Detection
Traditional fraud detection methods are mainly based on empirical rules and are unable to detect fraud in advance.
Taking car insurance as an example, there are relatively more entities involved in car insurance, including vehicles, owners, drivers, passengers, etc. It is very difficult to identify those entities among these data. However, in a graph database, it is possible to build a graph to see some outliers based on the number of claims or other business indicators, and it is also possible to classify groups with higher fraud rates through graph algorithms. In social relationship networks, the fraud possibility can be determined by the correlation with the blacklisted spots. In general, we can make full use of pattern matching and other graph database technologies to classify the major entities by using graph algorithms and then identify groups or individuals with high fraud rates based on business experience and existing fraud cases.
Fraud cases usually have certain characteristics. For example, a luxury used car with frequent accidents or multiple accident-related people driving a different vehicle frequently, or a high correlation between different vehicle groups and multiple accident-related owners. These are all suspicious characteristics that can be identified quickly and effectively by graph technology.
Scenario 3: Precision Marketing
In the scenarios of marketing, the data in a graph database can help identify target customers in depth. Based on the information left by customers, we can find social relationships, friends, and non-immediate family members other than immediate family members. Such relationship networks help us see a larger dimension of the customer's social circle. We can find more hidden relationships in the connections between customers and their friends. This can help us learn more about family insurance purchase behaviors.
In the private domain scenario, the marketing agents can recommend other insurance products based on the customer's purchase history. The groups with associated relationships may tend to prefer the same insurance products. From another perspective, such associated recommendations will be more convincing to customers. In the public domain scenario of getting target customers, graph databases can also help advertise to the target customers through the customer data system.
Scenario 4: Insurance Underwriting and Claims Fraud Detection
At the underwriting and claim stages, we can find what insurance policies the insured has, the number of claims denied, and the association with known fraud cases by querying the in and out-degree of the insured. As for car insurance, we can detect fraud from "the case" to the "vehicle", to the "owner", to the "driver", and to the "vehicle", as shown in the above figure. In this way, we can find the fraud cases from the root cause. For example, in a DUI transfer case (the drunk driver A contacts his relative B to arrive at the scene and report to the insurance company in place of A to get insurance compensation after the DUI accident), we can analyze behaviors such as outgoing and incoming calls, and the location information of the involver. Through this information, multiple risk factors may be detected such as delayed reporting, non-frequently used cell phone numbers and distance from the scene.
Scenario 5: Agents Management
A large number of domestic insurance agents and a high turnover rate may lead to difficulty in agent management.
We can also build the agent's relationship network based on the graph model. The agent's professional habits and complaints received can be labeled in the graph to enhance the screening of agents from the source.
For some underground insurance scenarios, such as forging the identity of a newcomer for commission. Fraud risks can be identified through cell phone numbers, electronic device numbers, IP associations, etc., all of which can effectively reduce customer complaints and insurance frauds caused by agents.
Why NebulaGraph?
Features of NebulaGraph
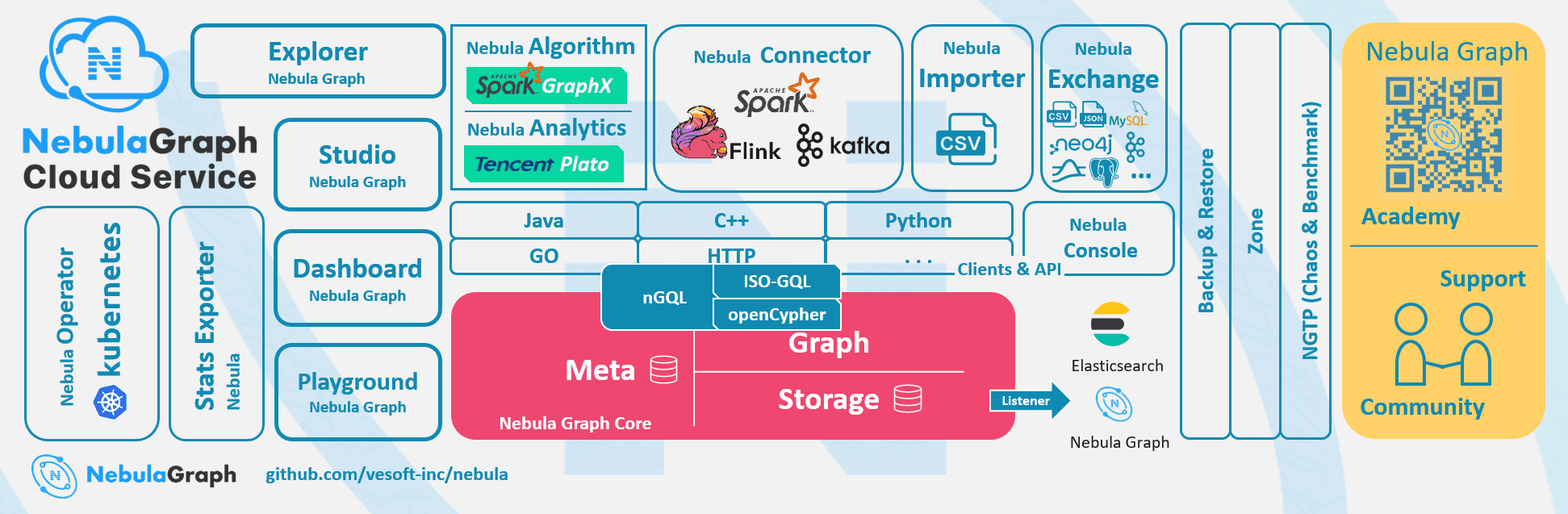
To address the above anti-fraud pain points and the need for the system-level construct, NebulaGraph has the following features that are suitable for the assurance risk control needs:
Multi-source data fusion: The sources of insurance data are diverse, including bank data, social network data, government data, medical data, marketing data, and so on. The data fusion of these data sources is a key to the success of the fraud detection system that can establish a comprehensive analysis of customers to better help insurance companies achieve automatic and accurate underwriting.
Support of graph data model: The construct of an underlying data model is the key to the multi-dimensional analysis. NebulaGraph data models fit the storage and query presentation requirements of linked data and provide quicker analysis compared to the relational model while its schema is flexible.
Cloud-native architecture: A good storage system should enable upper-tier applications to compute and scale horizontally based on business needs. NebulaGraph is a distributed cloud native graph database. It can be easily scaled out and scaled in to meet the needs of business growth and shrinkage.
Enterprise-level feature support: NebulaGraph, as a basic software, provides the support of peripheral tools for a better exploration and visual operation and maintenance.
Risk factor detection: NebulaGraph's association analysis and graph computing engines can help better identify the risk factors with algorithms.
Accuracy of auxiliary algorithms: Machine learning relies on input data constructed by tuples, which tend to ignore the relationships between data. So the input of graph data can be used to enrich the contextual information and thus improve the accuracy of relevant models.
In a word, NebulaGraph connects dimensional data. It can be used in different scenarios to help insurance companies effectively identify and avoid hidden risks at different stages. For details about how to deploy and use NebulaGraph, please refer to live demos.
