Architecture
Dec 30, 2019
An Introduction to NebulaGraph’s Query Engine
NebulaGraph
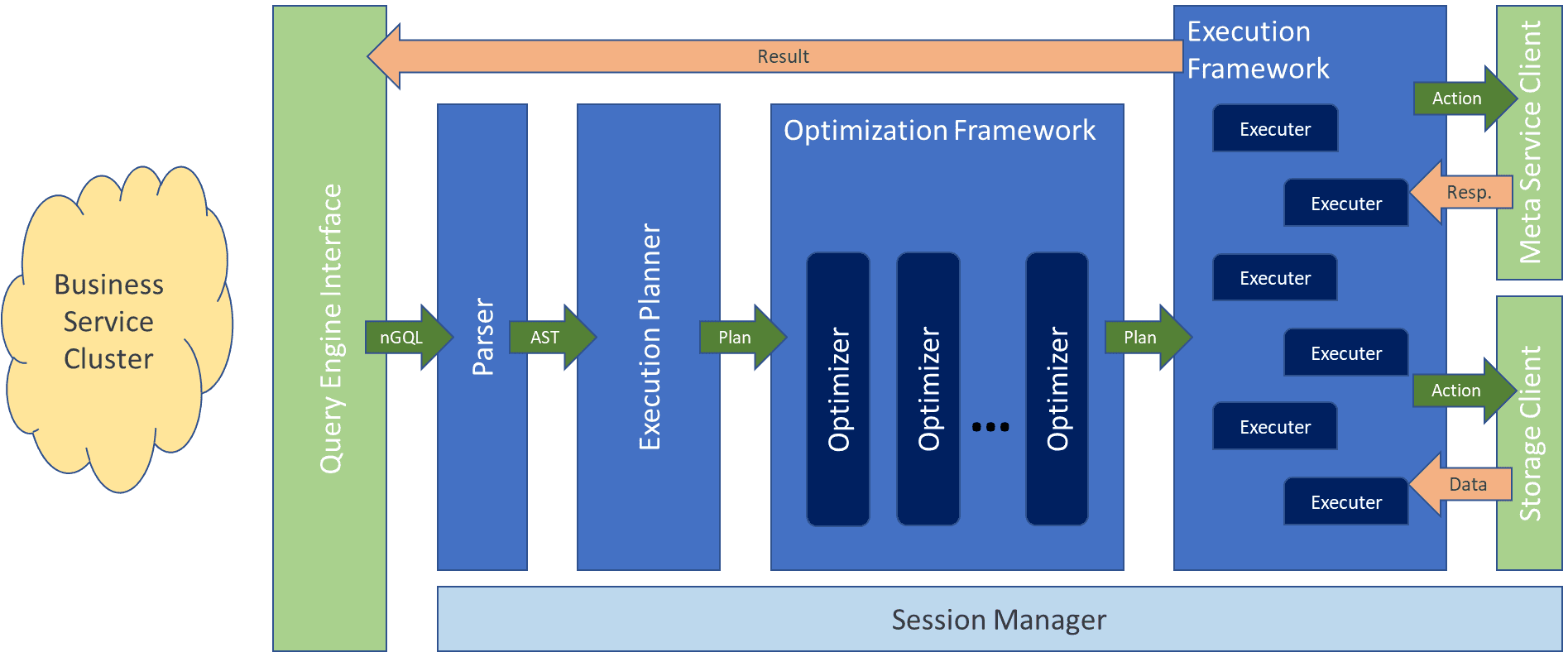
The query engine is used to process the NebulaGraph Query Language (nGQL) statements. So, an architectural overview of the NebulaGraph query engine is important.
In the below illustration is an overview chart of the query engine. If you are familiar with the SQL execution engine, this should be familiar to you. The NebulaGraph query engine is very similar to the modern SQL execution engine except for the query language parser and the real actions in the execution plan.
Session Manager
NebulaGraph employs the Role Based Access Control. So, when the client first connects to the Query Engine, it needs to authenticate itself. When it succeeds, the query engine creates a new session and returns the session ID to the client. All sessions are managed by the Session Manager. The session will remember the current graph space and access rights to the space. The session will also keep some session-wide configurations and be used as a temporary storage to store information across multiple requests in the same session.
The session will be dropped when the client connection is closed or is idle for a period of time. The length of the idle time is configurable. When the client sends a request to the query engine, it needs to attach the current session ID. Otherwise, the query engine will reject the request. When the query engine accesses the storage engines, it will attach the session object to every request. This is so the storage engine does not have to manage sessions.
Parser
The first thing that the query engine will do when receiving a request is to parse the statements in the request. This is done by the parser. Most of the parser code is generated by the famous flex/bison tool set. The lexicon and syntax files for the nGQL can be found in the src/parser folder in the source code tree. The nGQL is designed in a way that is close enough to SQL. The idea is to lessen the learning curve as much as possible.
Graph databases currently do not have a unified international query language standard. As soon as the ISO’s GQL committee releases their first draft, NebulaGraph plans to make nGQL compatible with the proposed GQL.
The output of the parser is an Abstract Syntax Tree (AST), which will be passed on to the next module, the Execution Planner.
Execution Planner
The Execution Planner will convert the AST from the parser into a list of actions (execution plan). An action is the smallest unit that can be executed. A typical action could be fetching all neighbors for a given vertex, getting properties for an edge, or filtering vertices or edges based on a given condition.
When converting AST to the execution plan, all IDs will be extracted. This is so the execution plan can be reused. The extracted IDs will be placed in the context for the current request. The context will also be used to store the variables and intermediate results.
Optimization
The newly generated execution plan will then be passed to the Optimization Framework. There are multiple optimizers registered in the framework. The execution plan will be passed through all optimizers sequentially. Each optimizer can modify (optimize) the plan.
In the end, the final plan can look dramatically different from the original plan. However, the execution result should be exactly the same as the original plan.
Execution
The last step in the query engine is to execute the optimized execution plan. It is done by the Execution Framework. Each executor will process one execution plan at a time. Actions in the plan will be executed one by one.
The executor will also do limited local optimization, such as deciding whether to run in parallel. Depending on the action, the executor will communicate with the Meta Service or the Storage Engine via their clients.
