Community Spotlights
Sep 14, 2021
NebulaGraph Source Code Explained: RBO
shylock.huang
In the last article, we introduced how an execution plan is generated. In this article, we will explain how an execution plan is optimized.
Overview
Optimizer is a component used to optimize execution plans. Database optimizers are usually divided into two categories:
Rule-based optimizer (RBO), which optimizes an execution plan according to the preset rules. All the conditions for matching and the optimization results are relatively fixed.
Cost-based optimizer (CBO), which calculates the cost of executing different plans based on the collected data statistics, and then chooses the least costly execution plan.
So far, only RBO has been implemented in NebulaGraph. Therefore, this article will focus on the implementation of RBO in NebulaGraph.
Structure of Source Files
You can find the source code of the optimizer in the src/optimizer directory. Here is the structure of the source files.
The testdirectory is for testing, the rule directory contains the preset rules, and the other source files are source code for implementing the optimizer.
In the src/service/QueryInstance.cpp file, you can find the entry into the query optimizer.
ThefindBestPlan function will call the optimizer to perform optimization and then return an optimized execution plan.
Optimization Process
From a topological point of view, an execution plan in NebulaGraph is a directed acyclic graph. It consists of a series of nodes, and each node points to its dependent nodes. In theory, each node can specify the output of any node as input. However, it is meaningless to use the result of a node that has not been executed, so only the nodes that have been executed will be used as the input. Additionally, an execution plan can execute some special nodes such as loops and conditional branches. Figure 1 shows the execution plan of GO 2 STEPS FROM 'Tim Duncan' OVER like.
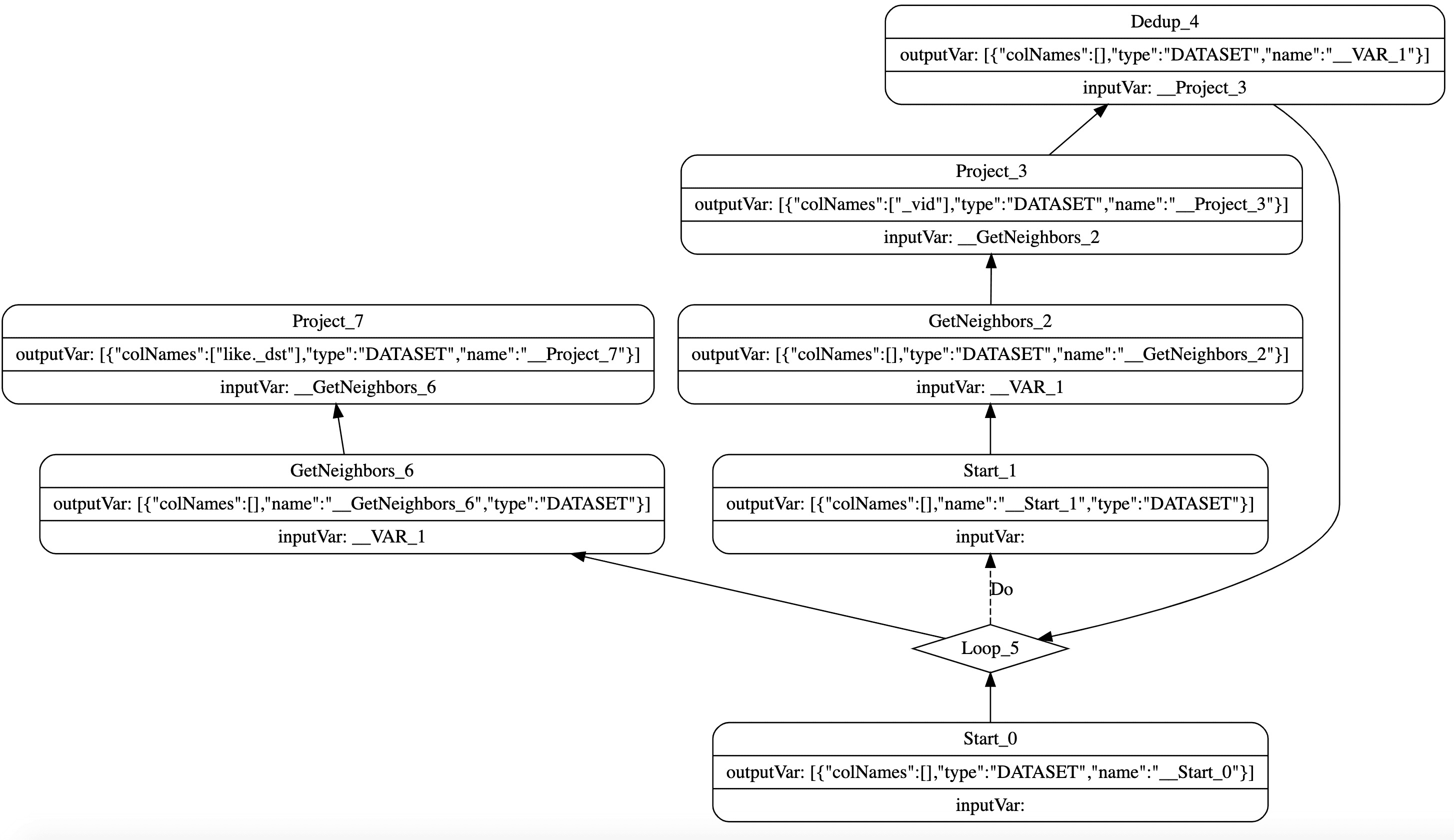
Figure 1
Currently, the optimizer in NebulaGraph mainly aims to perform pattern matching on the execution plan. If the matching is successful, an appropriate function will be called to transform the matched part of the execution plan according to the preset rules. Let's take the GetNeighbor -> Limit part of the execution plan as an example. The Limit operator will be merged to the GetNeighbors operator, so as to implement the pushdown optimization to operators.
Implementation
The optimizer does not operate directly on an execution plan, but transforms it to OptGroup and OptGroupNode first. OptGrouprepresents a single optimization group, which usually refers to one or more equivalent operators. OptGroupNode represents an independent operator and has pointers to dependencies and branches, which means that OptGroupNode retains the topological structure of an execution plan. Why is such a structural transformation needed? It mainly aims to abstract the topological structure of an execution plan, to shield some unnecessary details of execution such as loops and conditional branches, and to facilitate storing some contexts in the new structure for matching rules.
The transformation process is a simple preorder traversal during which the operators are transformed into the corresponding OptGroup and OptGroupNode. To facilitate your understanding of the following content, we call the structure composed of OptGroupand OptGroupNode an optimization plan, which is distinguished from "execution plan".
After transformation, rule matching and optimization plan transformation will be started. In this process, all the pre-defined rules will be traversed, and for each rule, a Bottom-Up traversal will be performed on the optimization plan for matching, which means the traversal starts from OptGroup at the deepest leaf node and then to that in the root node, but in each OptGroup node, a Top-Down traversal is performed on OptGroupNode inside to match the rule pattern.
As shown in Figure 2, the pattern for matching is Limit -> Project-> GetNeighbors. According to the Bottom-Up order, a Top-Down traversal is performed on the Start node first. Because Start is not Limit, matching fails. And then the similar matching failure occurs to the GetNeighbors node until Limit. When matching is successful, the transform function, defined according to the rules, will transform the part of the optimization plan that matches the rules. For example, in Figure 2, Limit and GetNeighbors will be merged.
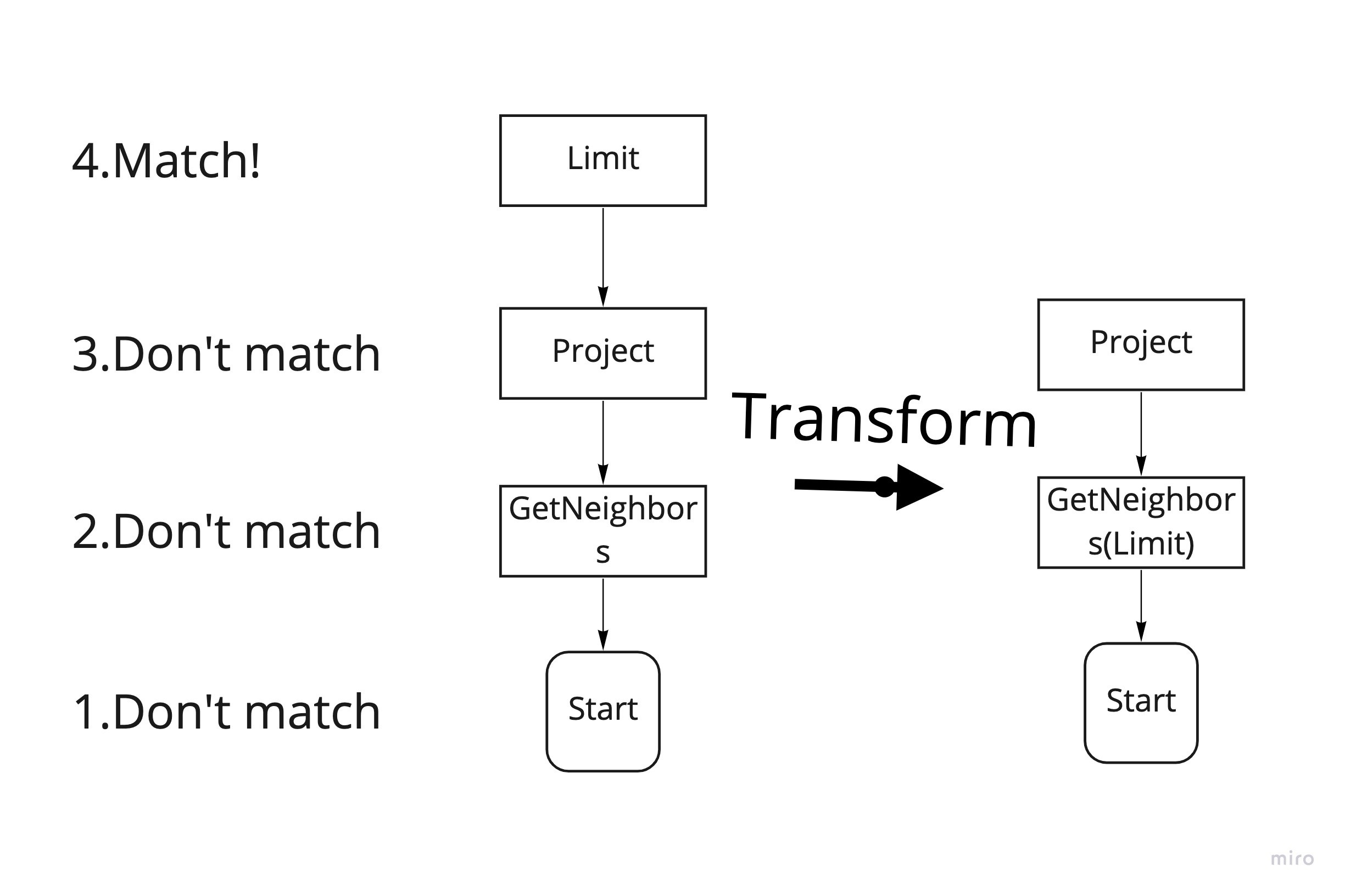
Figure 2
Finally, the optimizer will transform the optimized optimization plan into a new execution plan. The process of the last step is opposite to that of the first step, but it is also a process of recursive traversal and transformation.
Adding New Rules
In the preceding sections, we introduced how the optimizer is implemented in NebulaGraph. However, if you want to add rules for optimization, understanding too many implementation details is not necessary, but the knowledge of how to define a new rule is required. In this section, we will take the Limit pushdown as an example to show how to add a new optimization rule. You can find the source code of the rule in src/optimizer/rule/LimitPushDownRule.cpp.
To define a rule, the first thing is inheriting the OptRule class, and then implementing the pattern interface, where returning the pattern that needs to be matched is required. A pattern is a composition of operators and their dependencies such as Limit->Project->GetNeighbors. The next one to be implemented is the transform interface, which passes in an optimization plan for matching. This interface will analyze the matched optimization plan according to the pre-defined pattern and then optimize and transform the plan. For example, it merges the Limit operator and the GetNeighbors operator and then returns an optimized optimization plan.
When these two interfaces are implemented correctly, the new optimization rule can work.
This is all about RBO in NebulaGraph.
If you encounter any problems in the process of using NebulaGraph, please refer to "NebulaGraph Database Manual" to troubleshoot the problem. It records in detail the knowledge points and specific usage of the graph database and the graph database NebulaGraph.
Here is the link: https://docs.nebula-graph.io/2.5.0/pdf/NebulaGraph-EN.pdf
Join our Slack channel if you want to discuss with the rest of the NebulaGraph community!
