Deployment
May 6, 2021
Step by Step Tutorial: From Data Preprocessing to Using Graph Database
Jiayi98
This article is contributed by Jiayi98, a NebulaGraph user. She shared her experience in deploying NebulaGraph offline and preprocessing a dataset provided by LDBC. It is a beginner-friendly step-by-step guide to learn NebulaGraph.
This is not standard stress testing, but a small-scale test. Through this test, I got familiar with the deployment of NebulaGraph, its data import tool, its graph query language, Java API, and data migration. Additionally, now I have a basic understanding of its cluster performance.
Preparation
Internet connection is necessary for the following preparations.
Download an RPM file of Docker: https://docs.docker.com/engine/install/centos/#install-from-a-package
Download a TAR file of Docker Compose: https://github.com/docker/compose/releases
Pull the following images from https://hub.docker.com/search?q=vesoft&type=image and run docker save
image nameto save them to tar archives: nebula-metad, nebula-graphd, nebula-storaged, nebula-console, nebula-graph-studio, nebula-http-gateway, nebula-http-client, nginx, and nebula-importer.Copy and modify the YAML file from https://github.com/vesoft-inc/nebula-docker-compose/blob/docker-swarm/docker-stack.yaml
On the nebula-graph-studio GitHub page (https://github.com/vesoft-inc/nebula-web-docker), download its RPM file.
Installation
Install Docker.
Install Docker Compose.
Import the images.
On the manager node, run the following command to initialize the Docker Swarm cluster.
According to the prompt, on another machine, join the swarm as a worker node.
The following error may occur when a worker node joins a swarm.
Error response from daemon: rpc error: code = Unavailable desc = connection error: desc = "transport: Error while dialing dial tcp 172.16.9.129:2377: connect: no route to host"
You can try disabling the firewall as follows to solve this problem.
On the manager node, modify
docker-stack.ymland createnebula.env.
In the YAML file, the hostnames of machines must be different. If errors occur during the startup, please check your YAML file, which should be blamed for most errors. If you want to upgrade NebulaGraph from v1 to v2, replacing the images in the YAML file is enough.
On the manager node, deploy a NebulaGraph stack.
Here is how I debugged the deployment:
Install NebulaGraph Studio.
The source code in the folder is for NebulaGraph v1. If you are using NebulaGraph v2, find the source code in the subfolder v2.
OR
In the command, -d is added to run the container for the service in the background.
When the service starts, in the browser address bar, type http://ip address:7001
Test
The dataset in this test is provided by LDBC.
Prepare
Pull the source code from https://github.com/ldbc/ldbc_snb_datagen/tree/stable.To generate data for scale factor 1-1000, use the stable branch.
Download hadoop-3.2.1.tar.gz from http://archive.apache.org/dist/hadoop/core/hadoop-3.2.1/.
Preprocess the LDBC dataset.
Preprocess LDBC Dataset
Please make sure that the NebulaGraph version that you are using supports “|” as separator.
For an LDBC dataset, the IDs and indexes of the vertices and edges are not compatible with those in NebulaGraph. The vertex IDs must be processed to be unique keys.
In my case, a prefix was used for each vertex ID. For example, for a person vertex, a p was added to change the original ID 933 to p933. To try my CDH, I used Spark to preprocess the data and stored the data on HDFS for importing them into NebulaGraph with Nebula Exchange.
Hardware Specifications
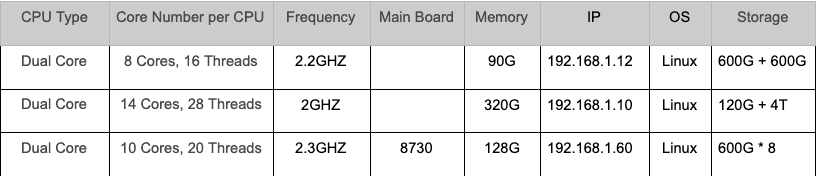
NOTE: An HDD is not recommended for NebulaGraph. However, I do not have an SSD. The test result proved that HDDs perform badly.
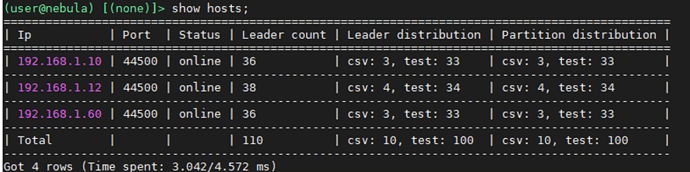
Service Distribution
Three nodes for the services:
192.168.1.10: meta, storage
192.168.1.12: graph, meta, storage
192.168.1.60: graph, meta, storage
Two graph spaces were created:
csv: With 10 partitions
Original data: About 42 MB
More than 7,000 vertices and 400 thousand edges
test: With 100 partitions
Original data: About 73 GB
More than 282 million (282,612,309) vertices and 1.10 billion (1,101,535,334) edges
When the data was imported to NebulaGraph, about 76 GB storage space was occupied, of which about 2.2 GB was occupied by WAL files.
I did not do a test on data import. Some data was imported with Nebula Importer, and the rest was imported with Nebula Exchange.
Do a Test
How to do the test:
Choose 1,000 vertices and obtain the average response time of 1,000 queries.

In the three-hop test, it was detected as "Timeout" because I set the timeout parameter to 120 seconds. Later, I performed a three-hop query on the terminal and found more than 300 seconds were needed.
I really hope this article could do some help to those who are new to NebulaGraph. I am grateful for all the technical support from the community and the NebulaGraph team.
NebulaGraph is really supportive of its users' attempts to learn it. I have gained a lot in the learning process.
