Tech-talk
How NebulaGraph Fusion GraphRAG Bridges the Gap Between LLMs and Enterprise AI
This blog post is based on insights shared by Zhechao Yang, VP of Product at NebulaGraph, exploring the critical intersection of graph databases and AI. It synthesizes key industry challenges and technological evolutions, focusing on practical applications and future trends.
Large language models (LLMs) promise to revolutionize industries, but a significant gap remains between this potential and their practical, scaled use in enterprises. Conventional Retrieval-Augmented Generation (RAG) systems often fall short because they fragment complex business knowledge, severing the deep semantic relationships and scattered context that are crucial for accurate understanding.
Fusion GraphRAG, pioneered by the NebulaGraph team, is the industry's first full-chain enhancement of RAG built upon a native graph foundation. It moves beyond disparate tools to intelligently fuse knowledge graph technology, document structure, and semantic mapping into a single, cohesive framework. This core advancement, engineered and powered by the high-performance NebulaGraph database, provides LLMs with interconnected, context-rich intelligence that reflects real-world business logic, transforming scattered data into reliable enterprise AI.
Why LLMs Struggle to Penetrate Core Industries
Despite massive investments, the widespread deployment of LLMs in mission-critical processes faces sobering hurdles. The root causes often boil down to two fundamental issues amplified by traditional data handling:
The Hallucination Problem
At their core, LLMs are probabilistic prediction engines. They are designed to generate plausible-sounding text, not to act as deterministic databases of facts. This inherent characteristic makes their output unreliable in scenarios demanding high accuracy, auditability, and trust—precisely the requirements of finance, healthcare, logistics, and telecommunications.
The Data Silo Problem
The most powerful general-purpose LLM is limited by the data it was trained on. Enterprise knowledge is inherently connected, but standard document processing severs these links. When content is broken into isolated chunks for retrieval, critical semantic relationships that span different sections or documents are lost. This leaves LLMs trying to answer complex questions with disconnected pieces of information, leading to incomplete or incoherent responses.
This divide creates a pressing need for a framework that grounds LLMs in verifiable, structured, and domain-specific knowledge.
GraphRAG: A Paradigm Shift from Retrieving Answers to Reasoning Over Facts
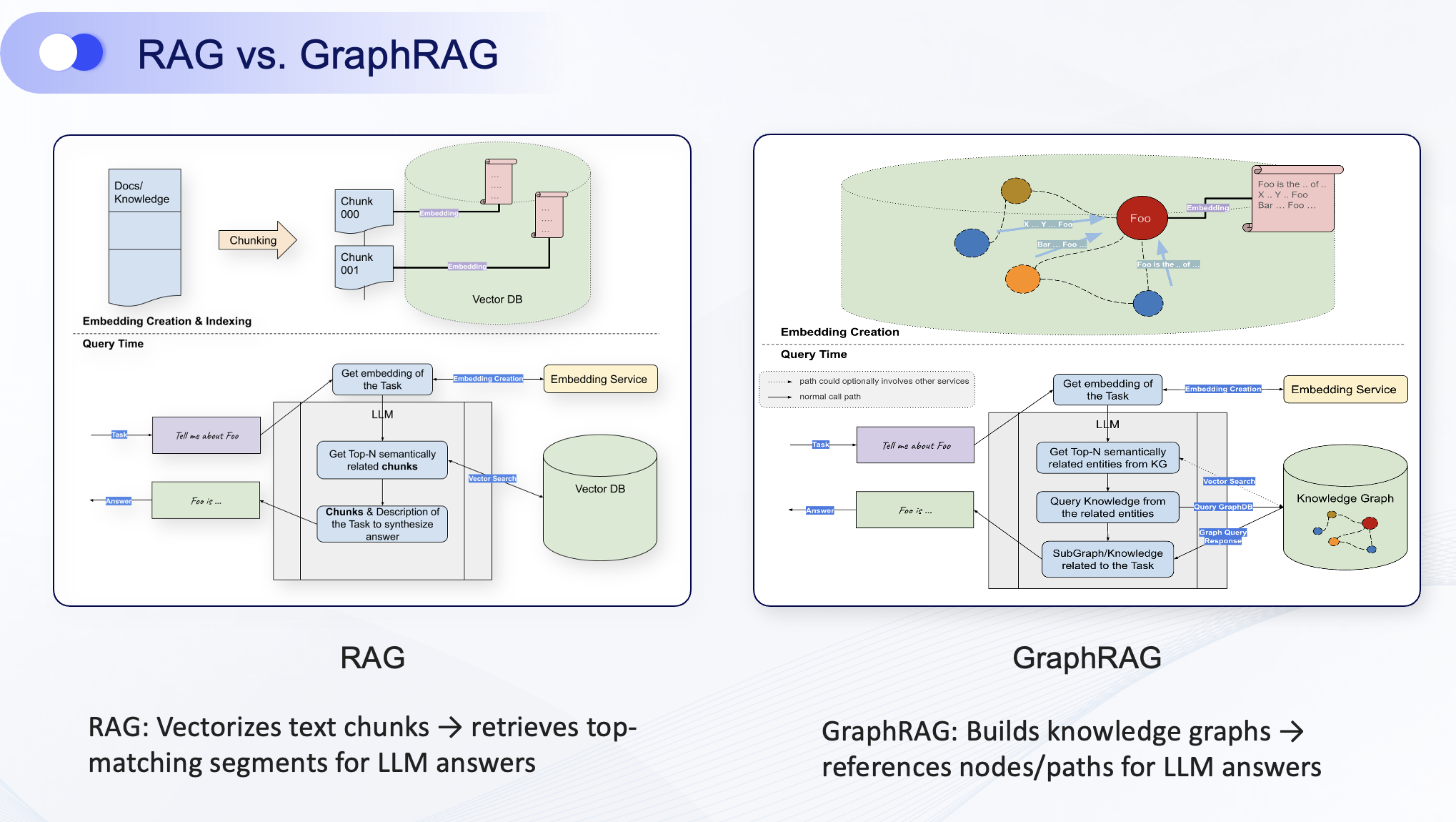
The recent success of "second-brain" AI assistants points the way forward. Their effectiveness hinges on a technique called Retrieval-Augmented Generation (RAG), which enhances an LLM's response by pulling in relevant information from an external knowledge source. Think of it as shifting the LLM from relying solely on memory to cross-referencing facts from a trusted library.
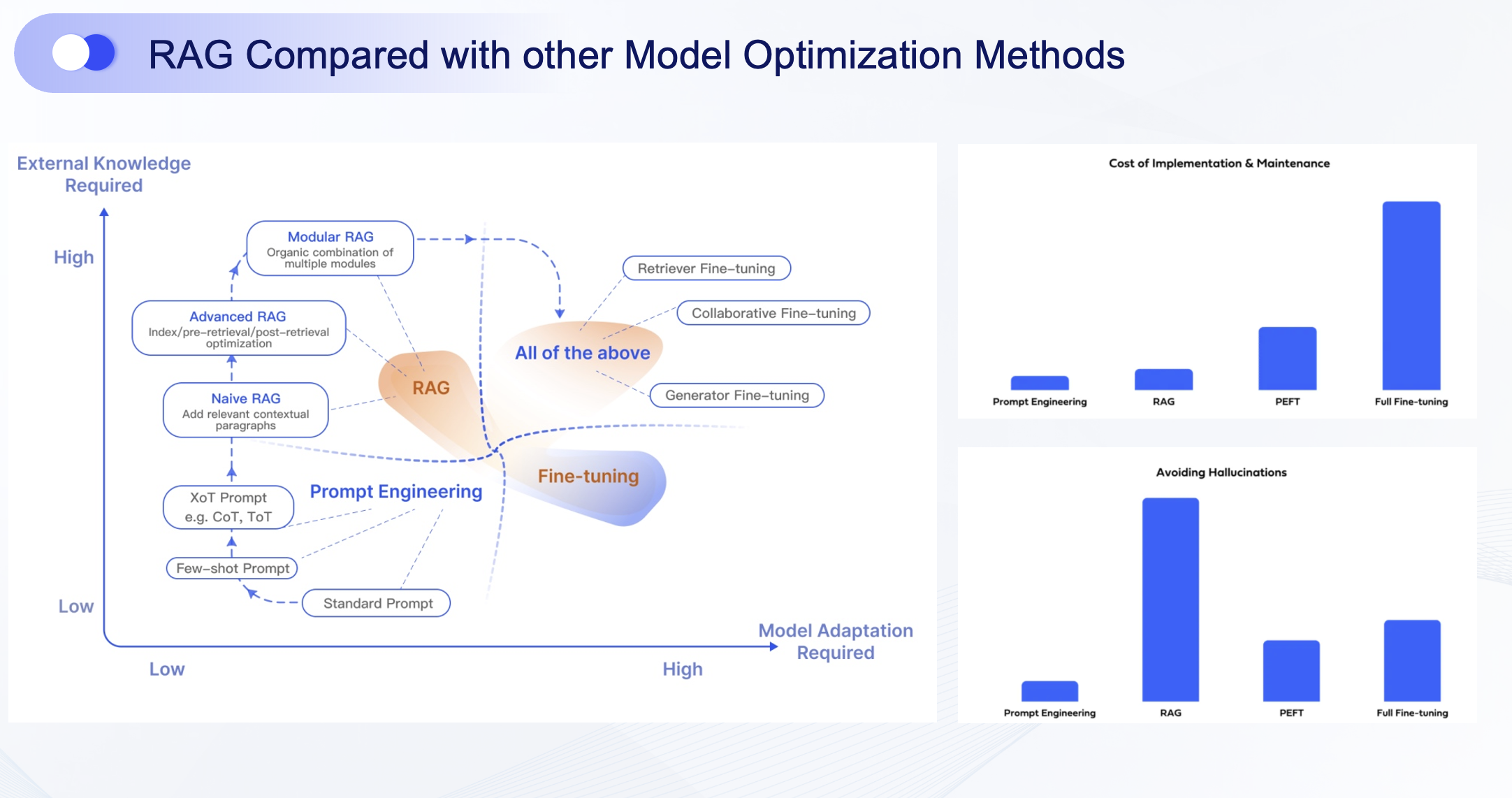
Currently, three primary indexing methods power RAG systems:
- Keyword/Full-Text Indexing: Relies on literal string matching. It's fast but lacks semantic understanding.
- Vector Indexing: Enables semantic search by mapping text to numerical vectors. It excels at finding conceptually similar content, powering recommendations, and Q&A.
- Graph Indexing: The core is uncovering and traversing relationships. It preserves the rich, interconnected context within data—how entities link, influence, and relate to one another—preventing information from being reduced to isolated chunks.
GraphRAG represents a revolutionary upgrade to traditional RAG. It deeply integrates knowledge graphs and graph technology into the LLM architecture. Instead of retrieving isolated snippets, GraphRAG allows the LLM to reason over a network of facts. This dramatically improves contextual relevance, enables multi-hop reasoning, and provides inherent explainability, as every conclusion can be traced back through a path of nodes and relationships.
The Challenges of GraphRAG
Despite its clear advantages, implementing GraphRAG has been prohibitive for many teams, facing two major barriers.
- High Technical Threshold
Building a knowledge graph traditionally requires a suite of NLP expertise—named entity recognition, relationship extraction, and entity linking—along with significant volumes of labeled data and model fine-tuning.
- High Operational Cost
The process of constructing, maintaining, and querying a graph for RAG was historically complex and resource-intensive, often requiring specialized infrastructure and expertise, making it orders of magnitude more costly than simpler vector-based approaches.
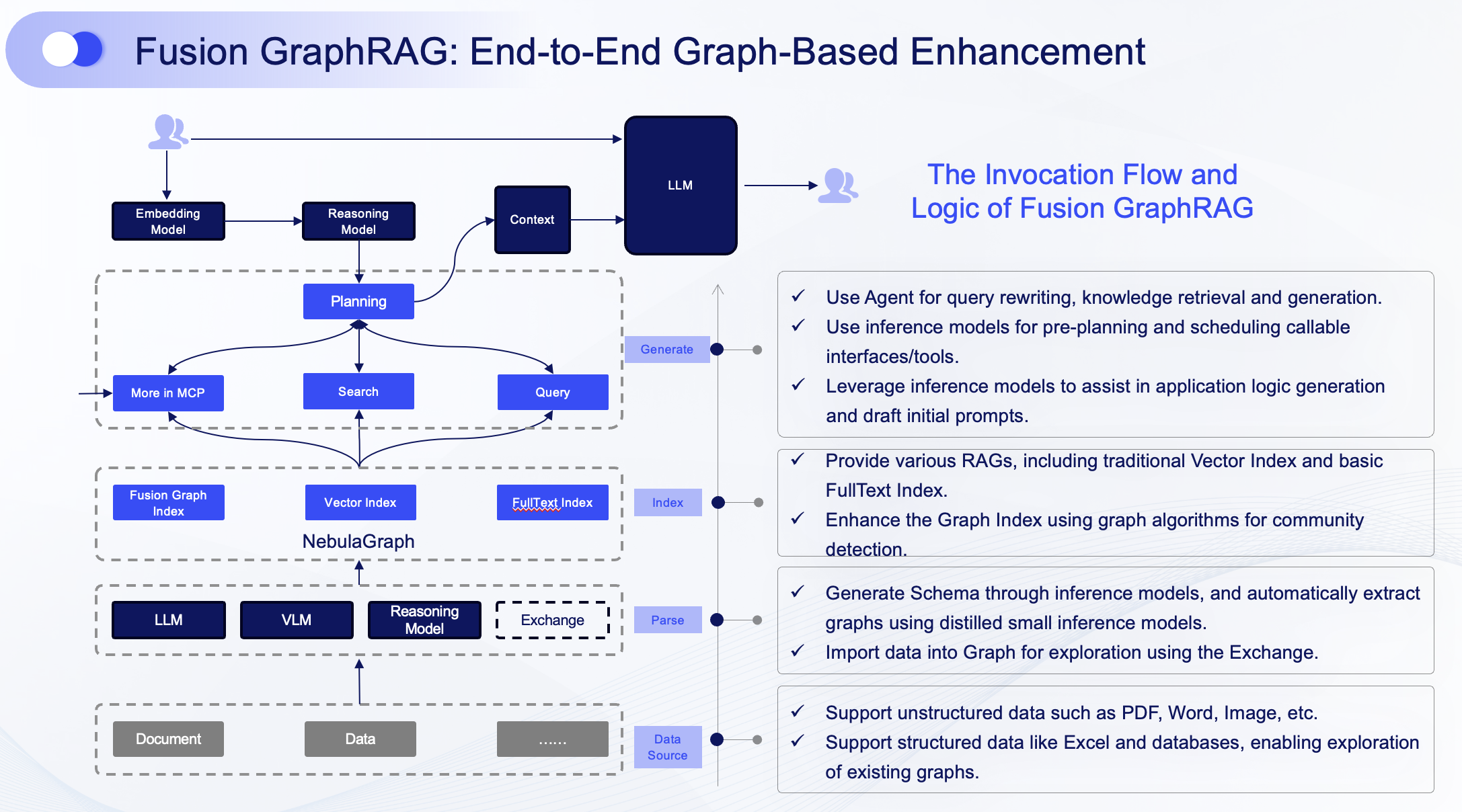
Fusion GraphRAG: The NebulaGraph Engineered Framework for Enterprise Intelligence
Building on the GraphRAG foundation, Fusion GraphRAG is our strategic framework designed to overcome the industry's two biggest adoption barriers: high technical complexity and inconsistent performance.
Unleashing Superior, Measurable Performance
Unlike traditional methods that treat different retrieval techniques as separate components, Fusion GraphRAG is architected from the ground up within NebulaGraph to create a synergistic system. This deep integration yields demonstrably superior results:
- Benchmark-Beating Accuracy: On open-source KG-RAG datasets focused on complex multi-hop questions, our framework achieves over a 10-percentage-point improvement in both recall rate and answer correctness compared to leading state-of-the-art (SOTA) methods. This quantifiable lead underscores its ability to handle intricate queries.
- Enterprise-Grade Reliability: In real-world deployments, the performance is even more striking. For instance, in a proof-of-concept using financial regulatory documents, a system built with NebulaGraph's Fusion GraphRAG achieved a 95% correctness rate, setting a new standard for reliable, mission-critical AI applications.
Industrializing Practical Implementation with NebulaGraph
We've engineered Fusion GraphRAG to move from a research concept to a production-ready tool, directly addressing the high technical and operational costs that have hindered GraphRAG adoption.
- Democratizing Knowledge Graph Creation: Built into the NebulaGraph ecosystem, our framework automates the complex pipeline of entity extraction, relationship mapping, and graph construction. What traditionally took weeks of data science effort can now be accomplished in hours, empowering domain experts to build and manage sophisticated knowledge graphs without deep NLP expertise.
- End-to-End Automation: From data ingestion to query serving, Fusion GraphRAG leverages NebulaGraph's native performance and scalability. This integrated toolchain eliminates the need to stitch together disparate systems, resulting in reported efficiency gains of 5–10x and significant cost savings for our early adopters.
Real-World Impact: From Post-Mortem to Proactive Intelligence
Consider the challenge faced by a major telecommunications provider. Network operators were overwhelmed by massive streams of alerts, forcing experts to manually sift through thousands of log lines to diagnose an incident—a slow and error-prone process.
A graph-powered solution transformed this by connecting work orders and alerts into a temporal knowledge graph. By applying graph algorithms to this interconnected model, the system could visually trace relationships and automatically pinpoint the most probable root cause.
The results were transformative:
- Positioning Accuracy improved to 85%.
- Mean Time to Resolution (MTTR) dropped from an average of 60 minutes to just 5 minutes—a 12x efficiency gain.
This methodology, applicable to any domain with complex event logs (finance, IT, manufacturing), highlights the shift Fusion GraphRAG enables: from reactive, post-mortem analysis to proactive, relationship-driven intelligence.
For those interested, you can refer to similar cases, such as 20-Second Root Cause Identification: BOSS Zhipin Builds Intelligent Operations and Maintenance Based on NebulaGraph
Conclusion: Building the Enterprise Knowledge Core with NebulaGraph
The future of enterprise AI lies in intelligent systems that understand how knowledge connects. Fusion GraphRAG is not just a concept but a core, productive innovation from NebulaGraph, designed to bridge the final gap between LLM potential and enterprise reality.
As the industry's most scalable and performant graph database, NebulaGraph provides the essential, high-performance infrastructure that makes Fusion GraphRAG possible. This combination transforms scattered enterprise data into a connected, dynamic "Enterprise Knowledge Core." This moves applications beyond basic retrieval toward reliable, contextual, and proactive decision-making—finally bridging the gap between the LLMs and the rigorous demands of enterprise AI.