Architecture
Dec 29, 2022
Integration Practice of OLTP and OLAP
Caton Hao
Dag Controller Introduction
Dag Controller is a component of NebulaGraph Explorer, which was released after several tests and tunings. It mainly solves the problem of integration of OLTP and OLAP, and the problem of graph algorithms in complex scenarios. To learn more, see https://docs.nebula-graph.io/master/nebula-explorer/deploy-connect/ex-ug-deploy/#dag_controller.
Below is some information I would like to share about Dag Controller. Feel free to leave a comment and let's discuss it together.
I'm sure you're no stranger to OLTP and OLAP, but let me briefly introduce them again here: OLTP is a fast-response, real-time online data processing method. OLAP is an offline, data algorithm method for complex scenarios. For NebulaGraph, OLTP has a variety of query statements, such as GO, MATCH, etc. OLAP has a variety of graph algorithms, such as Pagerank, Louvain, WCC (Weakly Connected Components), K-Core, and Jaccard.
OLTP and OLAP do not exist independently. For example, we can use the subgraph returned by a MATCH statement as input to the PageRank algorithm, and the result of the PageRank can be written to NebulaGraph to continue executing a MATCH statement or other algorithms. Like building blocks, various OLTP and OLAP can be assembled to form a data processing method for complex scenarios.
The Dag Controller is a system that handles scenarios where OLTP and OLAP need to be linked and executed.
Architecture
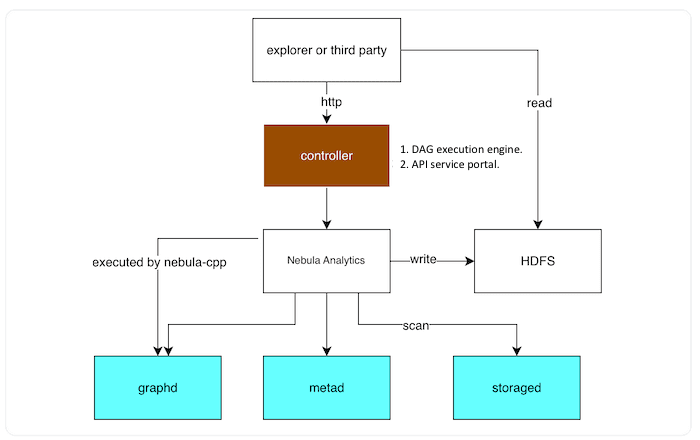
The responsibilities of Dag Controller:
It provides an HTTP interface for external communication and access.
It is used for job submission, stopping, deleting and other operations, as well as the configuration of the system environment.
Execution of DAG.
When Dag Controller executes DAG, the OLAP will call NebulaGraph Analytics, and the OLTP will call graphd to complete the execution of nGQL.
NebulaGraph Analytics is our graph computing system, supporting Pagerank, Louvain, WCC, Jaccard, and other graph algorithms, supporting HDFS and NebulaGraph data sources.
Graphd, metad, and storaged are components in NebulaGraph. Graphd is mainly responsible for nGQL parsing, storaged is responsible for data storage, and metad is responsible for metadata storage.
Cases
Case 1
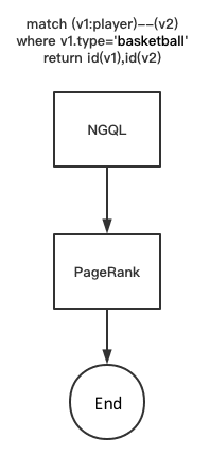
The above figure shows a DAG model that runs the pagerank algorithm on a subgraph. First, we get a subgraph using an nGQL statement, and then we run the pagerank algorithm on this subgraph.
This method can be used when our graph size is particularly large and we only want to run the algorithm on part of the graph data.
Case 2
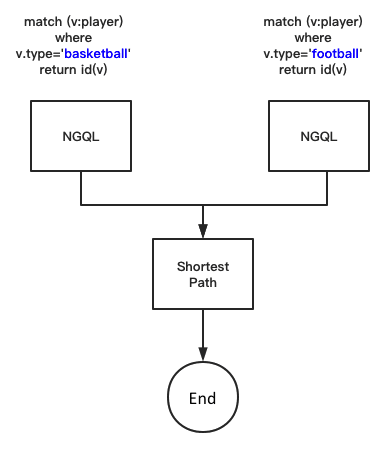
The above figure shows a model to compute the shortest paths for two classes of vertices.
First, the vertex IDs of the two classes are obtained separately by using nGQL, and then the vertex IDs of the two classes are passed to the shortestpath algorithm, which computes the paths between the two classes in the full graph.
Each algorithm can be set up to run the algorithm based on the full graph or subgraph.
There are various DAG models, and different DAG models can be built according to different business scenarios.
Technical implementation
DAG model
The DAG refers to a directed graph without loops, and an instance of DAG is considered as a job, and a job has multiple task.
The task in Dag Controller can be an nGQL or a graph algorithm such as PageRank, Louvain, SSSP, etc.
When a job is executed, it needs to sort the task first, there is a lot of related code on the internet, so I won't repeat it here.
Parallel execution
To ensure the execution efficiency of DAG, multiple DAGs need to be executed in parallel. At the same time, within a DAG, the task without upstream and downstream dependencies also needs to be executed in parallel.
How can multiple DAGs and tasks be executed in parallel? In simple terms, the DAGs and tasks are handled by two thread pools respectively.
The details are as follows:
When the system starts, allocate the job thread pool and task thread pool to handle the execution of job and task respectively.
Unexecuted jobs are periodically obtained from the database and transferred to the job thread pool.
When a job is executed, the task is sorted according to its upstream and downstream dependencies, and then it determines whether the execution of all upstreams of each task is completed, and then the task is handed over to the task thread pool for execution when the upstream execution is completed, or waits if the upstream execution is not completed.
If the job thread pool is full during job execution, you need to wait to obtain unexecuted jobs at regular intervals. The same is done when the task thread pool is full.
Type check
Note that the data type verification problem exists between the data input and output of tasks. For example, task2 is the downstream of task1. The input of task2 must be of type int, and the output of task1 must be of type int.
DAG stop
When you stop a job, you need to stop multiple task that are running in parallel. A task has a preparation phase, a running phase, and in the running phase there are cross-machine, multi-process situations. Stopping a job requires avoiding the orphan process problem.
Custom algorithm support
We support treating a customer's algorithm as a task for DAG building. First, configure the algorithm-related parameter information in the system. When executing a job, the system is responsible for running the algorithm that corresponds to the task.
