Architecture
Dec 27, 2022
NebulaGraph Database Architecture — A Bird’s Eye View
Sherman
NebulaGraph is a distributed graph database. We would like those who are interested in graph databases to know as much as possible about it. This includes how NebulaGraph is designed and why it is a highly performant database.
As a result, we have developed a series of graph database architecture articles. In them, we are going to cover three areas. First, we will provide a high-level overview of the architecture of NebulaGraph – the focus of this article. Next, we will cover how NebulaGraph’s storage engine works. And finally, we will illustrate how NebulaGraph’s query engine works, including how we have designed nGQL, our graph query language.
NebulaGraph Database Architecture Diagram
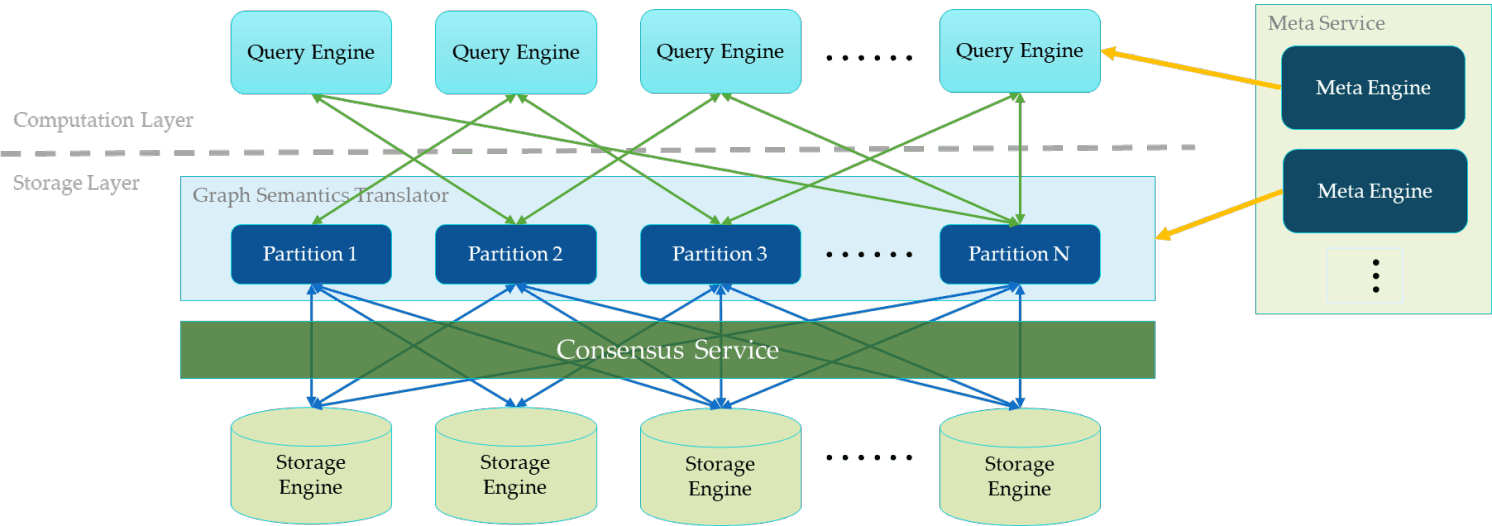
In the diagram above, there is a fully deployed NebulaGraph cluster that contains three services. They include a Meta Service, Query Service, and Storage Service. Each service has its own executable binary. These binaries can be deployed either on the same set of hosts or on different hosts.
Meta Service
In the below diagram, on the right side of the architecture diagram, it shows a cluster of Meta Service. The Meta Service follows a leader/follower architecture. The leader is elected by all Meta Service hosts in the cluster and serves all traffic. Followers stand by and take the updates replicated from the leader. Once the leader dies, one of the followers will be re-elected as the new leader.
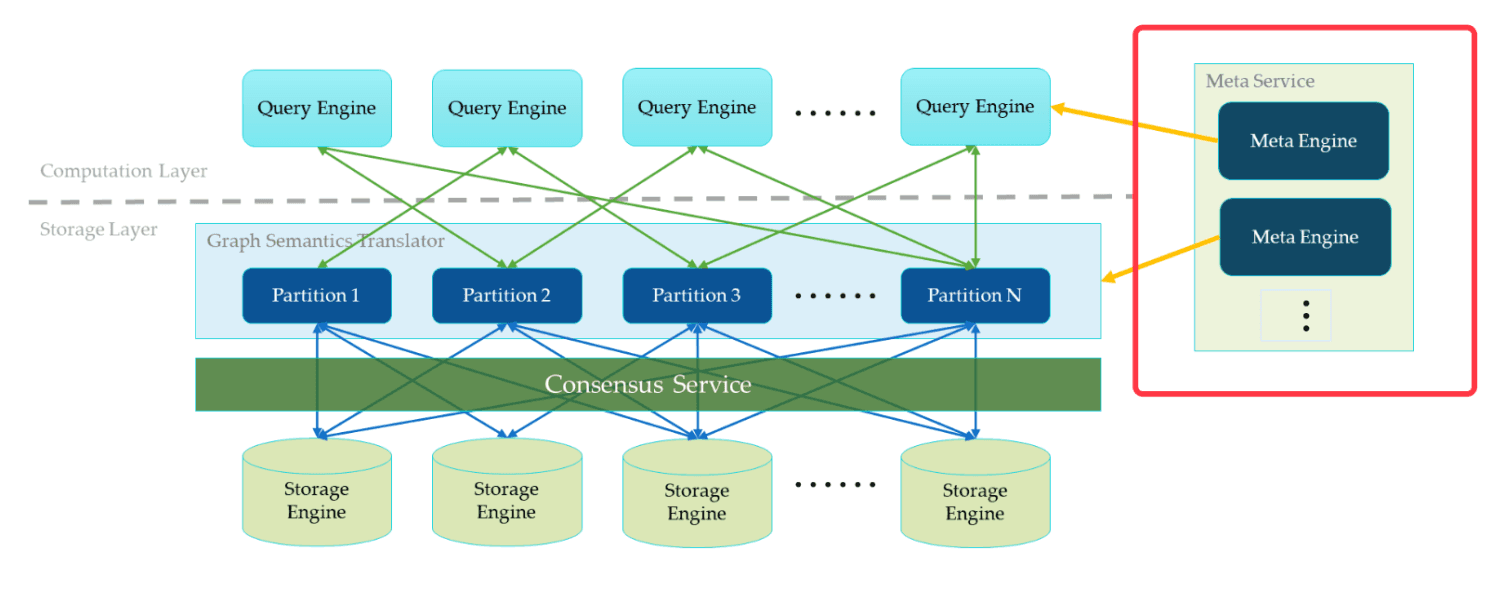
The Meta Service does not only store and provide meta information about the graph, such as schema and graph partition information. It also takes the role of the coordinator to orchestrate the data movement and to force the leader shift.
Separation of Query and Storage Layers
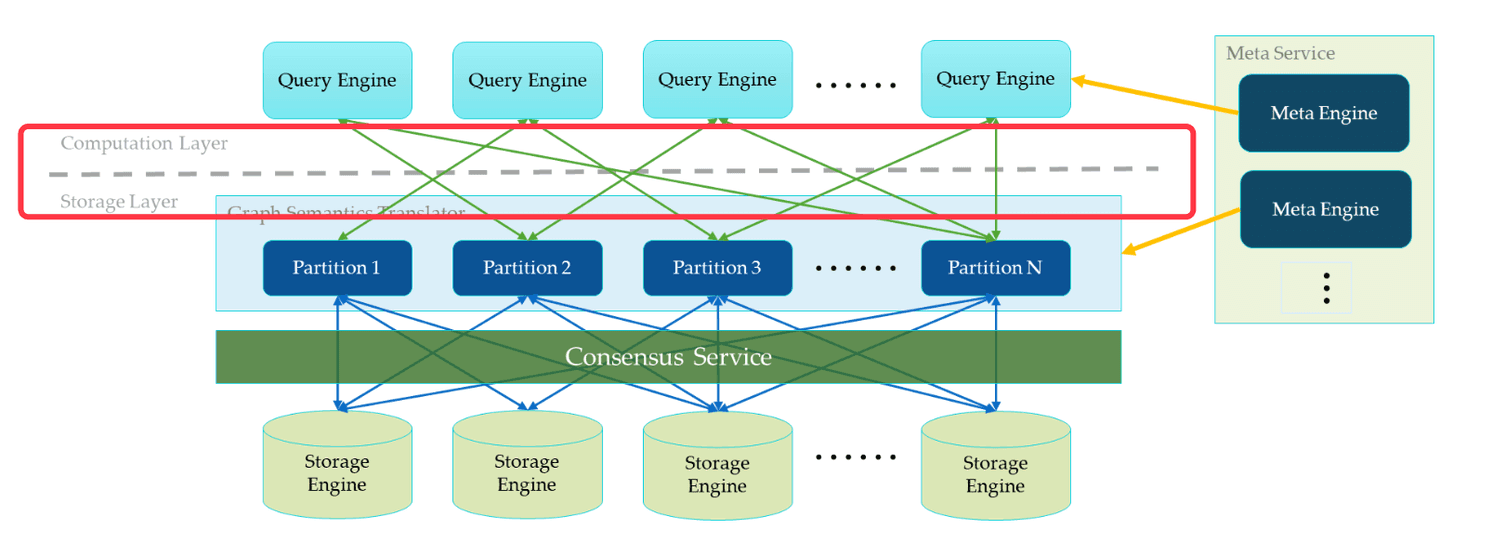
In the above diagram, to the left of the Meta Service, is NebulaGraph’s main services. NebulaGraph divides the query execution and the graph storage into two separate services. Above the dotted line is the Query Service. Below the dotted line is the Storage Service. This separation has several benefits. The most straightforward benefit is that the query layer and storage layer can be expanded or shrunk independently. The separation also makes the linear horizontal expansion possible. Last but not the least, the separation provides an opportunity to make it possible for the Storage Service to serve multiple computation layers. The current Query Service can be considered a high-priority computation layer. Meanwhile an iterative computation framework could be another one.
Stateless Query Layer
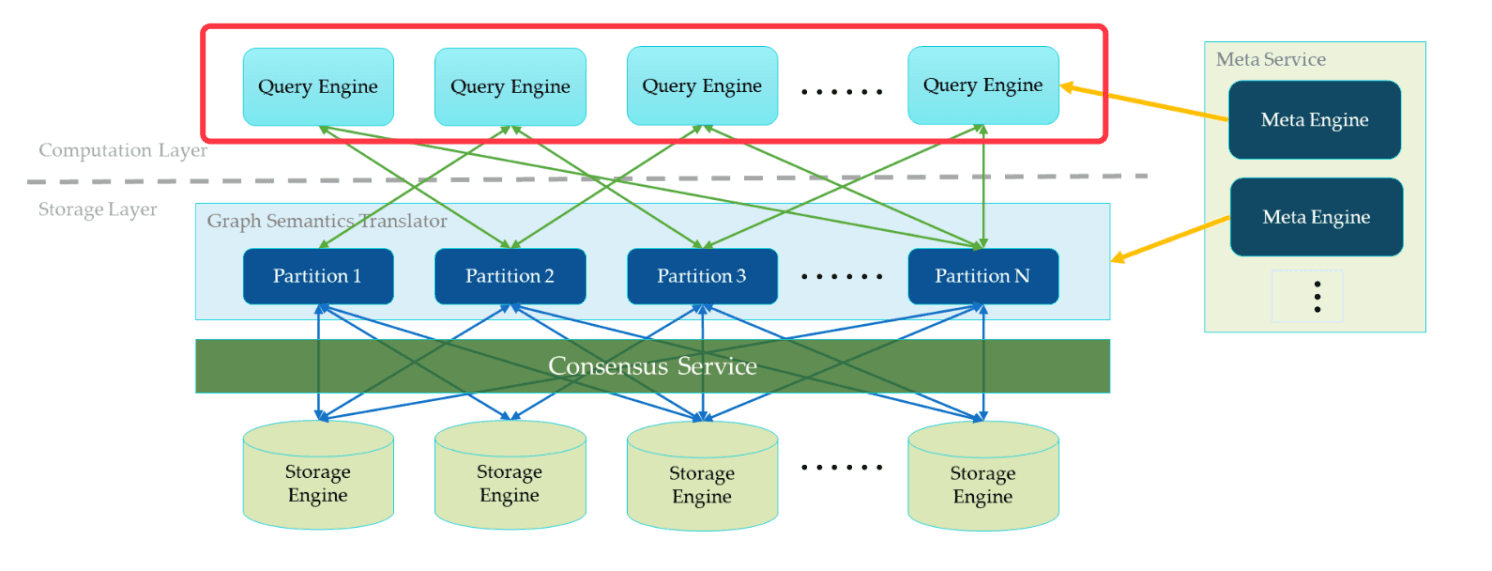
As to the Query Service, each individual Query Service host runs a stateless query engine. The Query Service hosts will never communicate with each other. They only read the meta information from the Meta Service and interact with the Storage Service.
This design makes sure the Query Service cluster can be easily managed by Kubernetes (aka. k8s) or be deployed on the cloud. A cloud deployment is already available for NebulaGraph. See how to deploy NebulaGraph on Kubernetes.
There are two ways to balance the Query Service load. The most common way is to place a load balancer in front of the Query Service. The second way is to configure the client library with all Query Service hosts’ IP addresses. The client will randomly pick one to connect to.
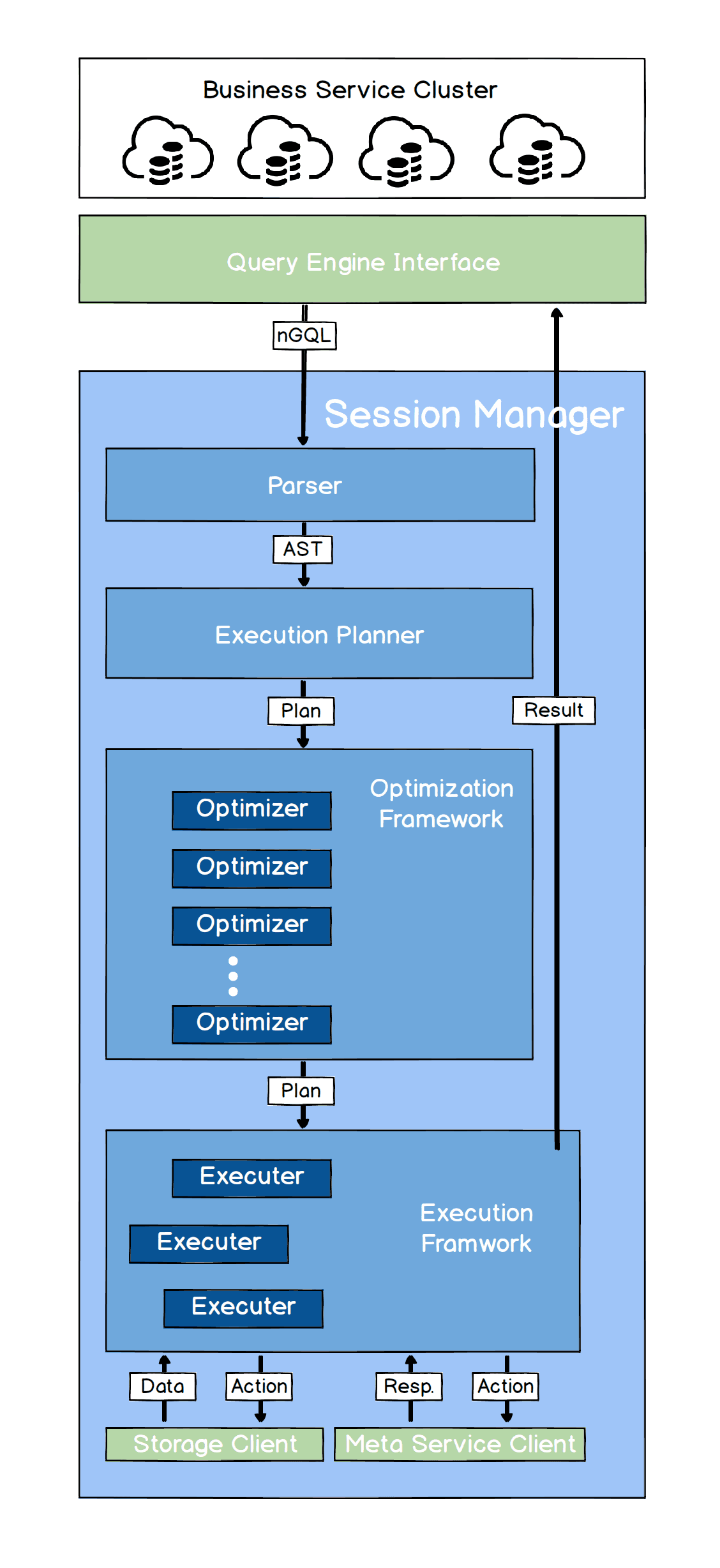
Each query engine takes the request from the client, parses the statement, and generates an Abstract Syntax Tree (AST). Then the AST will be handed over to the execution planner and the optimizer. The final AST will be passed to the executors.
Below is a flow chart of how NebulaGraph’s query engine works. For a detailed explanation, please refer to an introduction to the query engine.
Shared-nothing Distributed Storage Layer
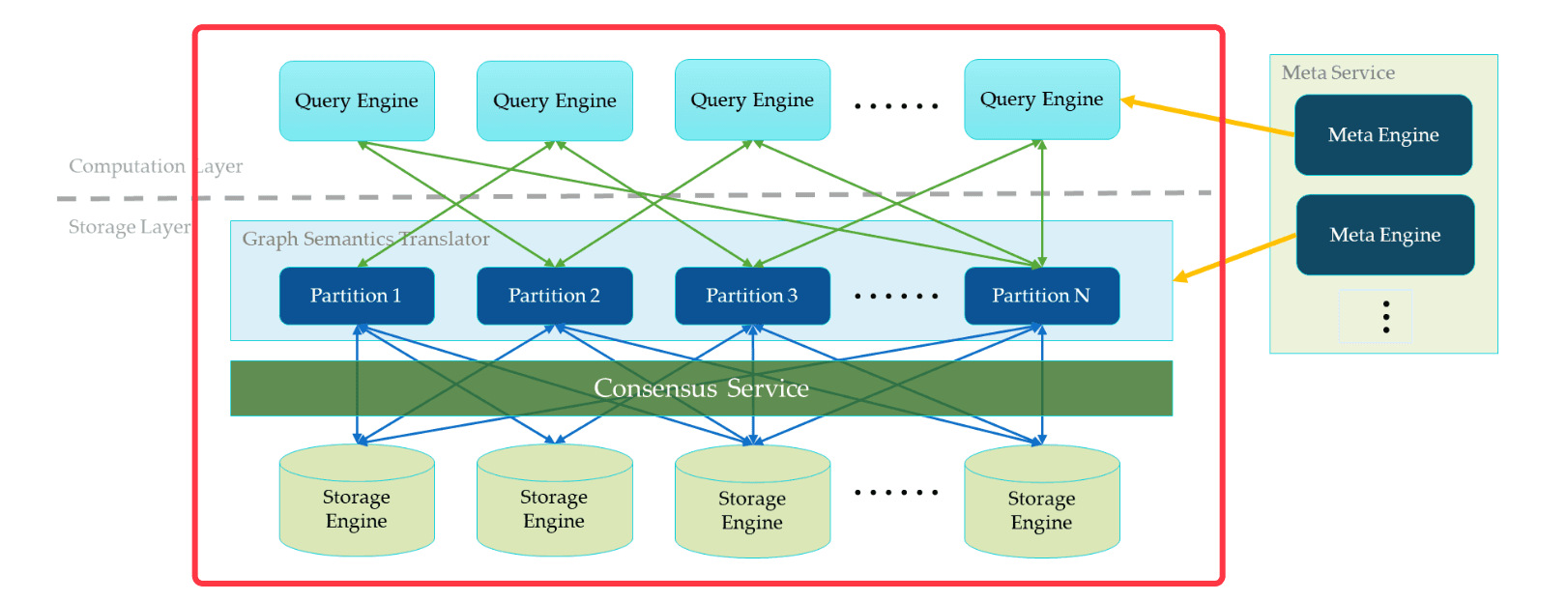
The Storage Service is designed to be a shared-nothing distributed architecture. Each storage host has multiple local key/value stores as the physical data storage.
A quorum consensus protocol (we chose RAFT over paxos due to its simplicity) is built on top of the key/value stores. Together, they provide a distributed key/value store. On top of this distributed key/value store, a graph semantic layer is provided. It translates the graph operations into key/value operations. The graph data (vertices and edges) are hashed into multiple partitions by the rule (vertex_id % the_number_of_partitions). A partition is a virtual set of data in NebulaGraph. These partitions are allocated to all storage hosts. The allocation information is stored in the Meta Service and can be accessed by storage hosts and query hosts.
Conclusion
This bird’s eye view into NebulaGraph covers the architecture to provide a basic understanding of how the distributed graph database works. For a more detailed introduction to the major components of the system, please refer to:
If you have anything to share about distributed systems or graph databases, please feel free to leave us a comment below. We look forward to hear from you.
