Architecture
Dec 26, 2019
An Introduction to NebulaGraph's Storage Engine
NebulaGraph
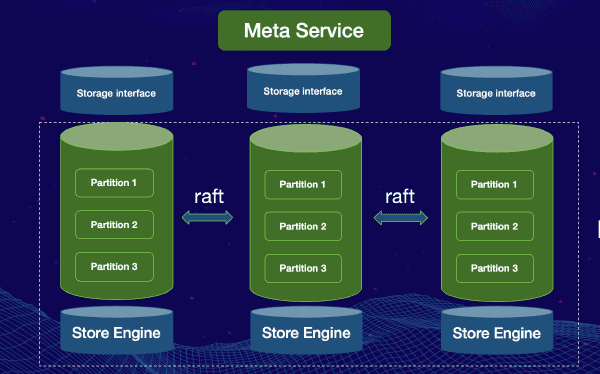
The Storage Service of NebulaGraph is composed of two parts. One is the Meta Service that stores the meta data. The other is Storage Service that stores the data. The two services are in two independent processes. The data and deployment are separated but their architectures are almost the same.
Architecture
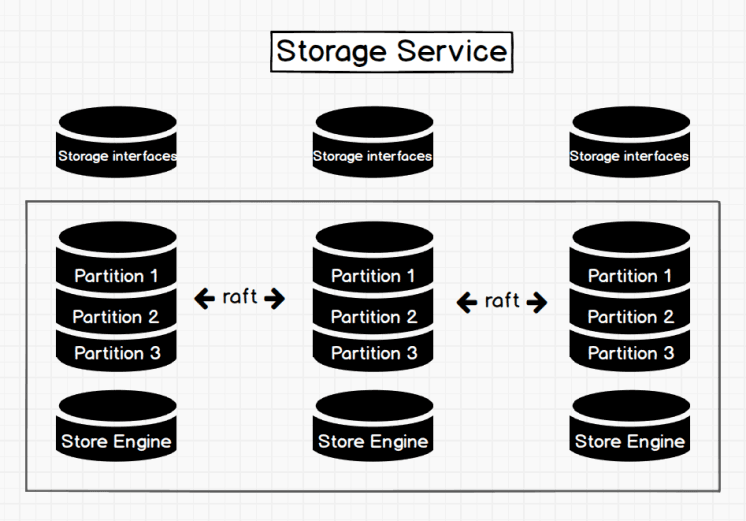
Fig.1 The Architecture of Storage Service
As shown in figure 1, there are three layers in the Storage Service. The bottom layer is the local storage engine, providing get, put, scan and delete operations on local data. The related interfaces are in KVStore/KVEngine.h and users can develop their own local store plugins based on their needs. Currently, NebulaGraph provides a store engine based on RocksDB.
Above the local storage engine is the consensus layer that implements multi group raft. Each partition corresponding to a raft group is for the data sharding. Currently, NebulaGraph uses hash to shard data. When creating a space, users need to specify the partition number. Once set, a partition number cannot be changed. Generally, the partition number must meet the need to scale-out in the future.
Above the consensus layer is the storage interface that defines a set of APIs that are related to the graph. These API requirements are translated into a set of kv operations targeting the corresponding partition. It is this layer that makes the storage service a real graph storage. Otherwise it is just a kv storage. NebulaGraph does not separate kv as an independent service. This is because a graph query involves a lot of calculation that uses schema, which does not exist in a kv layer. Such architecture makes pushing down easier.
Schema & Partition
NebulaGraph stores the vertices, edges, and properties. Efficient property filtering is critical for a Graph Database. NebulaGraph uses tags to indicate vertices types. One vertexID can relate with multiple tags, and each tag has its own properties. In kv storage, we use vertexID + TagID to represent a key and the related properties are placed behind a value after encoding. The format is shown in figure 2:

Fig.2 Vertex Key Format
Type: one byte, used to indicate key type, current types are data, index, system, etc.Part ID: three bytes, used to indicate the sharding partition. This field can be used to scan the partition data based on the prefix when re-balancing the partitionVertex ID: eight bytes, used to indicate vertex IDTag ID: four bytes, used to relate tagTimestamp: eight bytes, not available to users, used in MVCC in the future
Each edge in NebulaGraph is modeled as two independent key-values. One is stored in the same partition as the source vertex, namely out-edge. The other one is stored in the same partition as the destination vertex, namely in-edge. Generally, out-key and in-key are stored in different partitions.
There may be multiple edge types or multiple edges with the same edge type between two vertices. For example, if we define an edge type ‘transfer’, user A may transfer money to user B multiple times. Thus a field rank is added to distinguish the transfer records between the two. The edge key format is shown in figure three:

Fig.3 Edge Key Format
Type: one byte, used to indicate key type, current types are data, index, system, etc.Part ID: three bytes, used to indicate the sharding partition. This field can be used to scan the partition data based on the prefix when re-balancing the partitionVertex ID: eight bytes, used to indicate source vertex ID in out-edge, dest vertex ID in in-edgeEdge Type: four bytes, used to indicate edge type, greater than zero means out-edge, less than zero means in-edgeRank: eight bytes, used to indicate multiple edges in one edge type. Users can set the field based on needs and store weight such as transaction time, transaction number and weight of a certain orderVertex ID: eight bytes, used to indicate dest vertex ID in out-edge, source vertex ID in in-edgeTimestamp: eight bytes, not available to users, used in MVCC in the future
If the value of an edge type is greater than zero, the corresponding edge key format is shown in figure four. Otherwise if the value is less than zero, the corresponding edge key format is shown in figure five.

Fig.4 Out-key format

Fig.5 In-key format
The properties of vertices and edges are stored in the values of the corresponding kv pairs after being encoded. As a strong typed database, NebulaGraph needs to get the schema information in the Meta Service before decoding. In addition, when properties are encoded, the schema version is added to support online schema change.
NebulaGraph shards data through a modulo operation on vertex ID. All the out-keys, in-keys and tag data are placed in the same partition through the modulo operation on vertex ID. In this way, query efficiency is increased dramatically.
For online queries, the most common operation is to do a Breadth-First-Search (BFS) expansion from a vertex. Thus it is the basic operation to get a vertex’s in-edge or out-edge and such operation’s performance determines the traverse’s performance.
In BFS, there are cases for filtering some properties. NebulaGraph guarantees the operation efficiency by putting properties and vertices and edges together. At present, most graph databases verify their efficiency with Graph 500 or the Twitter data set, which are of no eloquence because properties are not included. While most cases use property graphs and BFS needs a lot of filtering as well.
KVStore
NebulaGraph develops its own kv store to meet performance needs:
High performance pure kv
Provided as a library, as a strong typed database, the performance of pushing down is the key of the performance of NebulaGraph
Strong data consistency, determined by the distribution system
Written in C++
For users who are not sensitive to performance or unwilling to migrate data, NebulaGraph provides plugins for the whole kv store and builds the storage service on the third party kv store. Currently, NebulaGraph provides the HBase plugin. With RocksDB as the local storage engine, NebulaGraph supports self-management of multiple hard disks to make full use of the parallel property. All users need to do is configure multiple data directories. NebulaGraph manages the distributed kv store in a unified scheduling way with meta service. All the partition distribution data and current machine status can be found in the meta service. Users can input commands in the console to add or remove machines to generate and execute a balance plan in meta service. NebulaGraph provides its own WAL mode so one can customize the WAL. Each partition owns its WAL to catch up data without WAL splitting to guarantee efficiency. In addition, NebulaGraph defines a Command Log class to conduct special operations. These logs have no real data and are only used to inform all replicas to execute certain operations with raft. NebulaGraph also provides a log class to conduct an atomic operation on partitions, such as with the CAS and the read-modify-write which fully uses raft serialization. One NebulaGraph kv store cluster supports multiple spaces, and each space is set with its own partition number and replica number. Different spaces are isolated physically. Spaces in the same cluster support different storage engines and sharding strategies.
The Raft Implementation in NebulaGraph
Multi Raft Group
As the log IDs must be serial, almost all the implementations adapt a Multi Raft Group to solve this problem. Therefore, the partition number almost determines the performance of the Raft Group. However, it does not mean the more partitions, the better the performance.
Each Raft group stores a set of state information and has its own WAL file. Thus, more partitions require more costs. Also, when there are too many partitions, the batch operation is meaningless if the load is not high enough. For example, with a single online system having 10,000 tps, if its partition number is greater than ten thousand, the tps of each partition per second is likely only 1. So, the batch operation loses its meaning and increases CPU cost.
There are two key points to achieve a Multi Raft Group. First is to share the transport layer because each Raft Group needs to send messages to the corresponding peers. If the transport layer cannot be shared, the connection costs are huge. Second is the threading model. With it, a Multi Raft Group must share a set of thread pools. Otherwise it will end with too many threads in the system, resulting in a large amount of context switch cost.
Batch
For each Partition, it is necessary to do a batch to improve throughput when writing WAL serially. In general, there is nothing special about a batch, but NebulaGraph designs a special type of WAL based on each part serialization. This adds some challenges.
For example, NebulaGraph uses WAL to implement lock-free CAS operations and each CAS operation will execute after all the previous WALs are committed. So, for a batch, if there are several WALs in CAS type, we need to divide this batch into several smaller serial groups.
Learner
New machines need to “catch up” data for quite a long time, and there may be accidents during the process. If a new machine joins the raft group as a follower, it will reduce the HA capacity of the entire cluster. NebulaGraph uses the command WAL mentioned above to implement its learner. If the leader encounters the add learner command when writing WAL, it will add the learner to its peers and mark it as a learner, so the logs will send to them as normal. But the learners will not be involved in the leader’s election.
Transfer Leadership
Transfer leadership is extremely important for balance. When moving a partition from one machine to another, NebulaGraph first checks if the source is a leader. If so, it should be moved to another peer. After data migration is completed, it is important to balance the leader again, so that the load on each machine can be balanced.
When transferring leadership, note that the leader abandons its leadership and the follower starts a leader election. When a transfer leadership command is committed, the original leader abandons its leadership. And as for followers, when receiving the command, it starts a leader election. This uses the same execution process with a common raft leader election. Otherwise, some corner cases will occur.
Membership Change
To avoid split-brain, when members in a Raft Group change, an intermediate state is required. In such a state, the majority of the old group and new group always have an overlap. Thus it prevents the old or new group from making decisions unilaterally. This is the joint consensus mentioned in the thesis. To make it even simpler, in his doctoral thesis Diego Ongaro suggests adding or removing a peer once to ensure the overlap between the majority of the new group and the old group . NebulaGraph‘s implementation also uses this approach, except that the way to add or remove a member is different. For details, please refer to addPeer/removePeer in the Raft Part class.
Snapshot
When the leader changes during sending snapshot, the follower may only receive half of the snapshot data. So, a partition data cleanup is required. Because multiple partitions share a single storage, how to clean up the data is a cumbersome problem. In addition, during the snapshot process, a large amount of IO is generated. Considering performance, you do not want this process to share an IO threadPool with the normal Raft. The process requires a large amount of memory. Thus, how you optimize the memory usage is critical for performance.
Storage Service
getNeighbors: query the in-edge or out-edge of a set of vertices, return the edges and the corresponding properties, support conditional filtersInsert vertex/edge: insert a vertex or edge and its propertiesgetProps: get the properties of a vertex or an edge
Graph semantics interfaces are translated into kv operations in this layer. To improve the performance of traversal, concurrent operations are also required.
Meta Service
On the kv store interface, NebulaGraph encapsulates a set of meta-related interfaces. Meta service supports CRUD on schema, cluster management, and user management. Meta service also supports single-machine deployment and multiple replicas to ensure data security.
