Performance
Apr 17, 2023
What is a Graph Database and What are the Benefits of Graph Databases
Min. WU
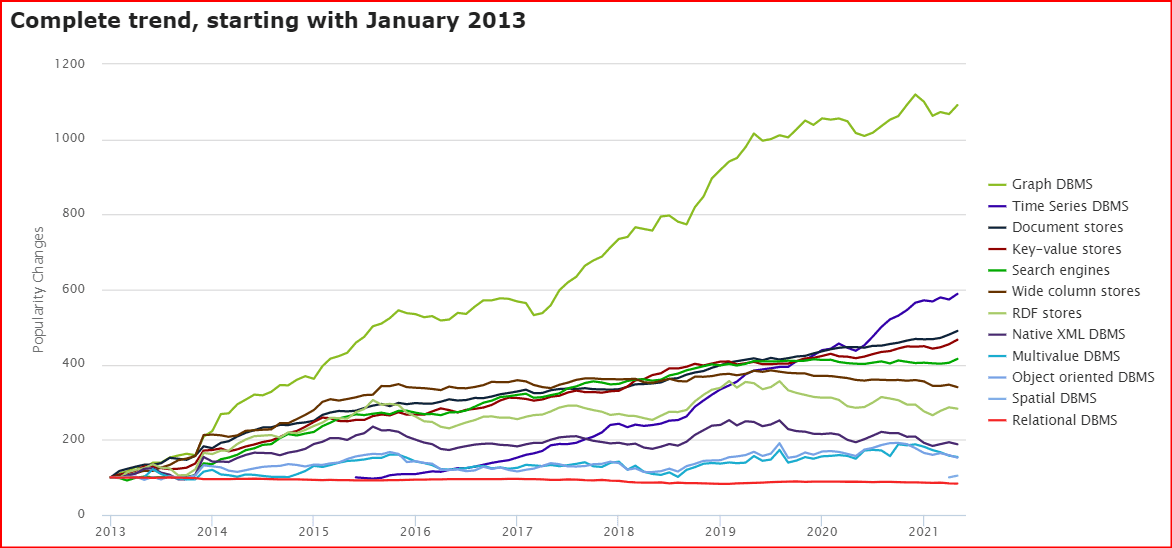
Graph databases are growing at an impressive pace, increasingly becoming the go-to DBMS for a growing number of large organizations. DB Engine, a website dedicated to the ranking of database management solutions, shows that graph databases have experienced consistent popularity since 2013 when many companies started appreciating them. The growth actually surpasses all other forms of DBMS. The worldwide graph database market is expected to increase to 11.25 Billion by 2030, rising from 1.59 Billion in 2020. This enormous surge is driven by the high need for elastic online schema environments.
What is a graph database
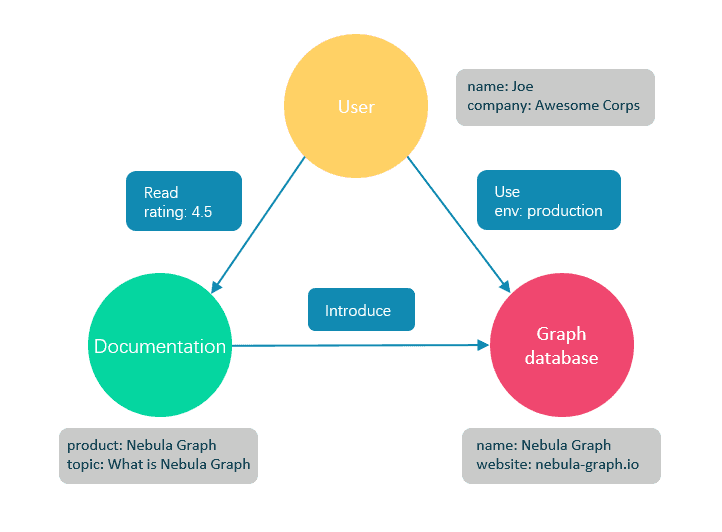
A graph database is a type of NoSQL database that is designed to handle data whose relationships are as crucial as the data itself. Unlike traditional Relational Database Management Systems (RDBMS), which store data in predefined table formats, graph databases represent data as a network of nodes (entities) and edges (relationships), closely mirroring how data is structured in the real world. Each node and edge can have properties associated with them, offering a rich and flexible schema that can evolve over time.
Graph databases excel in managing highly connected data and complex queries because they inherently map and store interconnections, which allows for high-performance traversal and retrieval operations. This capability makes them particularly suited for applications that require the analysis of complex relationships, such as social networks, recommendation engines, fraud detection systems, and more.
Types of graph databases
Graph databases can be categorized into two main groups based on data model and storage.
Data model-based graph databases
There are three major types under this category namely the property paragraph, RDF graphs, and hypergraph
1. Property graph
Property graphs organize data in relationships, nodes, and properties and store the data on relationships or nodes.
Nodes are entities and can hold multiple attributes called properties. You can tag nodes with labels that represent their roles in a domain. In addition, labels can attach metadata, like constraint or index information, to specific nodes.
Relationships provide relevant connections between different nodes. The relationship is directed, named, and has a start and end node. Furthermore, relationships have quantitative properties like distances, costs, ratings, weights, strengths, and time intervals. Relationships are efficiently stored, and thus nodes can share relationships without compromising performance. The navigation of relationships can be done in either direction, despite the fact that they are stored in one direction.
2. Hypergraph
Hypergraphs are data models that allow relationships to connect to multiple nodes by allowing several nodes at either end. This will enable users to analyze and store data with numerous many-to-many relationships. The relationships in a hypergraph are referred to as hyperedges.
In contrast to property graphs, hypergraphs have multidimensional edges, making them more generalized. However, the two are isomorphic, meaning you can present a hypergraph as a property graph, but you can’t do the opposite.
3. Resource description framework (RDF)
An RDF, or triple store, stores data in a three-part format of subject-data-object data structure. A separate node is used to present any additional information. RDF graph models are made of Arcs and Nodes, and the graph notation is presented by two nodes, one for the subject and another for the object, and an arc presents the predicate.
Triple stores are categorized as data model-graph databases because they process logically linked data. However, their storage engines are not optimized for property graphs, nor do they support index-free adjacency; thus, they aren’t native graph databases.
RDFs can scale horizontally but can’t rapidly transverse relationships because they store triples as individual elements. They must create connections from independent facts and add latency to perform graph queries. Triple stores are mostly applied in offline analytics because of their shortcomings in latency and scale.
Storage-based graph databases
This category contains three major types as well, namely the native storage graph, relational storage, and key-value store graphs:
1. Native graph storage
Native graph storage uses edge and vertex units to store and manage graph databases. It is best suited for multiple-hop or deep-link graph analytics. Native graph storage is designed to maximize traversal speed in arbitrary graph algorithms.
2. Relational storage
This graph database stores the edge and vertex table using a relational model. During runtime, relational “JOIN” concatenates (links) the two tables. The relational model represents data in tables using an intuitive and easy-to-understand way. Each row is a record with a key, which is the unique ID. Each column holds an attribute of the data, and each record has the attribute’s value. This makes it easy to identify the relationships between data points.
3. Key-value store
A key-value store is a non-relational database that uses NoSQL databases to store data. It stores data in key-value pairs where the key is the unique identifier. The keys and values range from complex compound objects to simple objects. Perhaps the best benefit of a key-value graph DB vs relational DB is that the key-value graph is highly partitionable. As a result, it allows horizontal scaling that most database types cannot achieve.


How graph databases work
A graph database is a kind of NoSQL database. It's a type of database that focuses on storing data as entities and their relations.
Graphs are a natural way to model complex relationships in data, such as user profiles, social connections and recommendations.
The term "graph" might seem a bit abstract, but it actually refers to a type of data structure that's used to model relationships between different pieces of information. For example, if you have a list of friends and their contact information, you can use a graph databaseto store this data in the form of nodes (pieces of information) and edges (connections between them).
Graph databases are different from other types of NoSQL databases because it stores data as nodes (vertices) and edges, rather than as rows and columns. This makes them ideal for storing highly connected data, such as social networks or recommendation systems.
They are used for a variety of applications, including social networking, recommendation systems, fraud detection and analysis, and logistics.
Why choose a graph database for your business
You should choose graph databases because they perform way better at scale compared to other DBMS. They make it possible to represent data in a much more intuitive way, a versatile way of visualizing data which enhances query performance and enables businesses to make valuable decisions like never before. They are also less intense in terms of computational demands.
This is important because for many businesses, the ability to store, visualize, query, and analyze data at a deeper level is key to success these days. Traditional databases can maintain large amounts of data and are capable of running complex queries, yet they rely on rigid and often complex schemas. An alternative solution is a graph database that stores information as interconnected points. The interconnected structure helps to connect objects according to specific criteria, allowing data teams to find themes or patterns within the data more easily than with a traditional approach.
Queries in a graph database run much faster, as they don't have to traverse entire tables or deal with foreign key constraints. In addition, since relationships between entities are stored, the data remains consistent even when it changes over time.

Benefits of graph databases
The key benefit of graph databases is the ability to handle big data that is deeply interconnected. As we are right in the middle of the data era, this one perk will prove invaluable to businesses that are focused on boosting their success through big data.
Here are the comprehensive benefits of graph databases:
1. High performance
Graph databases allow users to query linked data quickly and efficiently, making them much faster than traditional relational databases. With sophisticated algorithms and powerful search functions, graph databases can return complex query results across an interconnected network in milliseconds.
Querying in traditional databases can become slow very quickly when dealing with more complicated and larger data sets. Conversely, the performance of graph databases will remain consistent, no matter how large or complex the data is.
For example, NebulaGraph can so easily store and process graphs with trillions of edges and vertices - the only open source graph database that is capable of doing this!
Also read: NebulaGraph joins Data Benchmark Council
2. Data integrity
Graph databases are designed to maintain the integrity of data connections across a wide variety of data sources and formats. By connecting disparate pieces of information in a graph, organizations can ensure that their data remains consistent and accurate throughout their applications.
Instead of simply storing individual pieces of information in a database, graph databases link related data together using connected nodes and edges. This allows users to easily visualize highly connected data and establish how any changes to the data will affect other areas, hence enhancing data integrity.
3. Enhanced contextual awareness
Because graph databases store data in the form of relationships between objects, they enable users to uncover nuances in interactions that may not be evident at first glance with traditional techniques such as tabular relational models or hierarchical tree structures.
This enhanced contextual awareness helps organizations make better decisions by leveraging high level insights from their data. This is a crucial benefit in the modern business landscape where there is far too much data that is just idle. Graph databases can mine this data and deliver transformative insights to spur organizational growth.
4. Scalability
The schema and structure of the graph model is incredibly adaptable and can keep up with the high pace of ambitious data teams. There's no need to go through the long-winded process of modeling domains; just add to the current structure without disrupting its existing functionality.
Traditional database technologies often reach a scalability bottleneck when trying to bridge multiple sources of data. But graph technologies avoid this issue entirely with their distributed nature which allows more flexible scaling up or down as needed.
NebulaGraph provides linear scalability, enabling users to expand the cluster with additional nodes or services without interfering with performance.
5. Agility
Today's development landscape is rapidly evolving. It's all about flexibility and quick changes as needs are regularly shifting. Graph databases are the ideal solution for this kind of adaptive environment, where unified progress and management is becoming the standard.
Check out the fundamental differences between relational databases and non relational databases.
Use cases for graph databases
Did you know that all the top tech giants such as Facebook and Google are already utilizing the revolutionary power of graph databases to build products that generate mega revenues? All these companies use graph databases in a broad range of products, harnessing the force of big data connections to build irresistible products.
The use cases can be as vast as the imagination of any ambitious business. Here are the most interesting ones.
1. Recommendation engines
Real-time recommendation systems are very popular these days, especially in retail e-commerce, travel and social networks . The purpose of a recommendation engine is to predict customer preferences and recommend products or services they might be interested in whenever they are using your platform. The application of recommendation engines is quite exciting and is already being used by many companies to achieve immense success. But it would have been impossible to get this done were it not for graph databases.
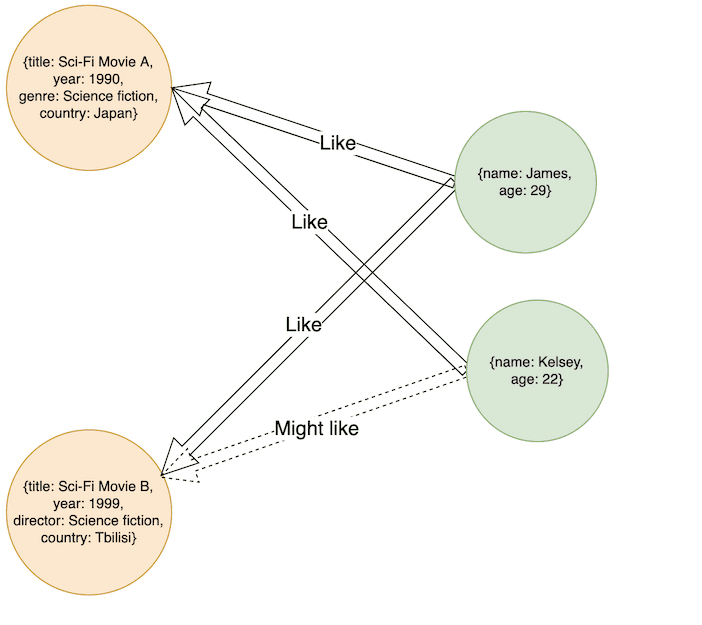
With graph databases, you can easily discover connections and generate recommendations for users. These recommendations are based on powerful graph analytics that match preferences with relevant products or services.
2. Fraud detection
Graph databases are being used to detect fraud by tracking transactional relationships between entities over a period of time.
By uncovering patterns of behavior across multiple financial transactions, it is possible to detect anomalies that could indicate fraudulent activities.
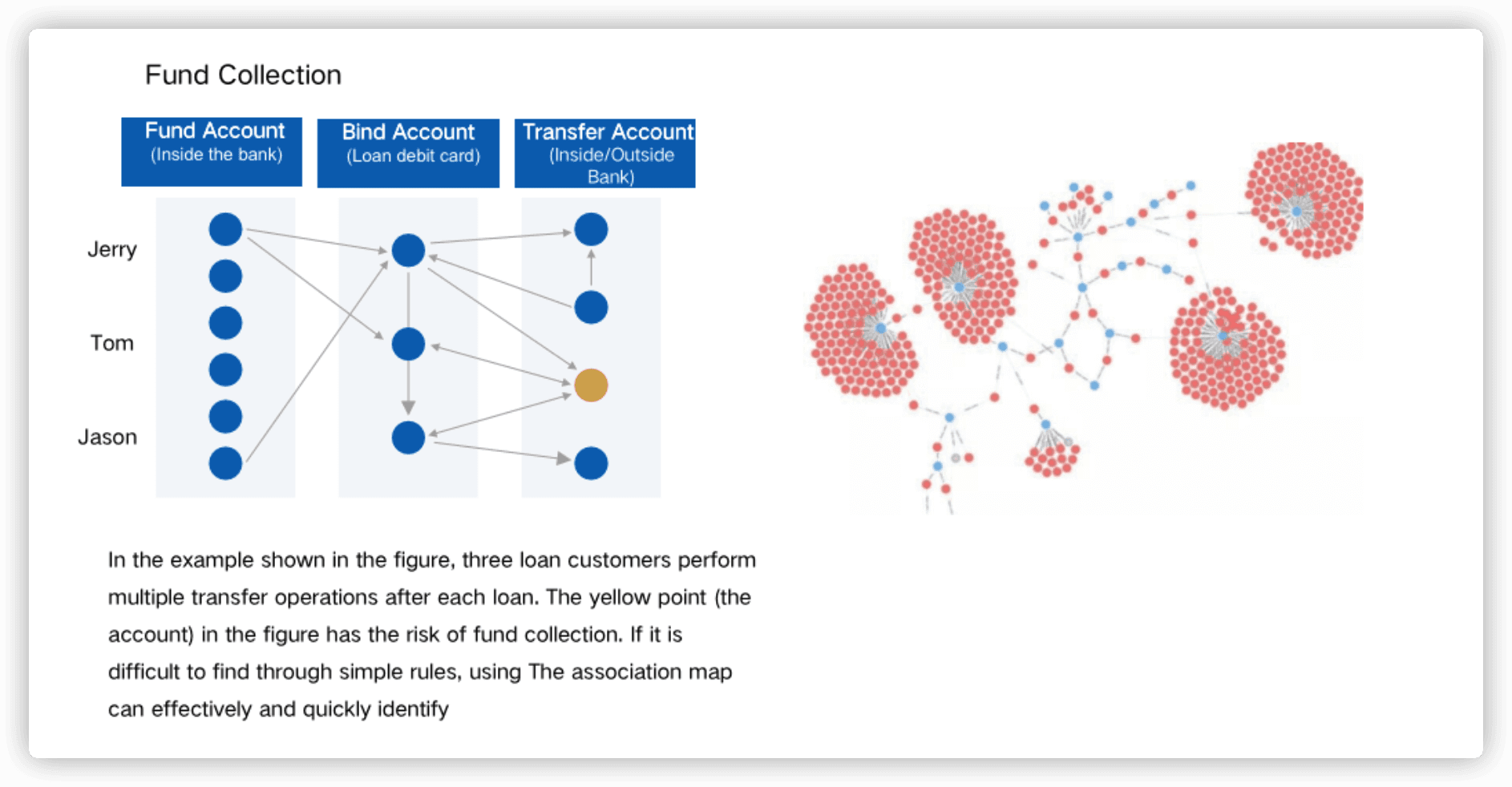
3. Network Analysis
Graph databases can be used to trace connections between technology components such as wireless routers, cables and microwave links, providing administrators with useful insights such as the types of connections being used at any given time.
This is important because network administrators have an ever-increasing responsibility when it comes to managing digital networks. They must be able to identify problems quickly and ensure that operational performance is maintained. They can use graphs to quickly find out which paths data packets take through the network by understanding IP addresses and traffic flow over large portions of the infrastructure. This way, they can know exactly where problematic areas are during troubleshooting or when planning upgrades or changes in configuration.
4. Power grid scheduling
Utility power grids are some of the most complex infrastructures in existence, requiring a fine balance between efficient usage and stability. Traditional models used for managing these grids relied heavily on tables and relational databases, leading to slow response times when working with high levels of data. However, graph databases can revolutionize how utility grids are scheduled.
Graph databases store nodes and edges that represent real-world relationships, allowing more precise and detailed understanding of the power grid's dependencies. By organizing data into separate networks, utility providers can quickly make decisions regarding load shedding, rotational outages, or even unexpected problems like capacitor failures.
In addition to providing flexibility in scheduling decisions, graph databases can also detect patterns of consumer behavior which can then be used to anticipate upcoming demand changes in order to deliver superior service while reducing costs.
5. Chatbot systems
Graph databases provide a flexible and easily navigable structure that allows bots to quickly access data and respond to queries in real time. Large datasets can be retrieved at high speeds, be used to construct a useful inventory of customer preferences and generate meaningful dialogue based on the collected insights.
Questions are organized in natural language and converted into knowledge graphs which are stored in graph databases. A semantic parser is used to resolve the questions in a question-answer format. The answers are then retrieved from the knowledge graph and passed on to the user.
6. Social networking
Social networking is a very popular use case for graph databases. Graph databases such as NebulaGraph is specifically designed to support social networks. A social network is a way of representing relationships between people or things. They are often represented visually in the form of graphs that show how things are connected. Graphs can be used to represent both online and offline relationships between people; for example, Facebook uses them to represent friendships between users and LinkedIn uses them to represent professional connections between users.
Latest trends in graph database
Graph database is a somewhat novel piece of technology and it is consistently evolving. The field was once dominated by traditional powerhouse Neo4j, but now the market is much more dynamic, with new players like NebulaGraph, AWS Neptune, and Janus Graph.
Graph databases have been around for more than 20 years. They were first used by computer scientists working on artificial intelligence (AI) projects, who needed a way to model complex systems that can't be represented as tables or lists of records.
Today, businesses are increasingly using graph databases for their own needs. The graph database market is expected to grow from $1.59 billion in 2020 to $11.25 billion by 2030, according to Emergen Research.
The popularity of graph databases has been driven by several factors:
Data grows rapidly — Every day we generate more than 2.5 quintillion bytes of data globally. This is expected to grow exponentially over time as sensors become more prevalent, mobile devices become more ubiquitous and machine-to-machine communication increases
Data types vary widely — From unstructured text documents and images to structured data such as financial transaction records or sensor readings, many different types of data exist today
Data distribution varies widely — Data can be distributed across multiple locations at different scales (local vs global) and in different formats (JSON vs XML).
Because of the explosion of global data volume and the distribution of data, graph databases are becoming more important and are adapting themselves to these trends.
Here are some of the latest trends in the graph database field.
Distributed graph databases
Distributed graph databases is the latest trend in graph database as global data grows rapidly. A distributed database is a database that is split into multiple servers, so that the throughput and storage capacity of the entire system is greater than the sum of its parts.
A distributed graph database is a database that consists of two or more files located in different sites either on the same network or on entirely different networks. Portions of the database are stored in multiple physical locations and processing is distributed among multiple database nodes.
Distributed databases provide high availability and fault tolerance because they maintain multiple copies of data that can be accessed through processes known as replication and shadowing. The cost of maintaining such systems has traditionally been considered too high for general purpose applications like spreadsheets or word processors, but with the advent of inexpensive disk storage there are now many applications that require such features.
Distributed databases are ideal for large-scale applications with complex data requirements, such as e-commerce systems and the Internet. They can also be useful when there are some constraints on the location of the data — for example, if you need to keep certain records in a certain jurisdiction (eg. the EU) because they contain sensitive information or if you have regional offices that need to share data across their networks.
The technical and cost advantages of distributed systems (like NebulaGraph) over single machines (e.g. Neo4j) or small machines are more obvious due to the increasing volume of data and computation. Distributed systems allow applications to access these thousands of machines as if they were local systems, without the need for much modification at the code level.
NebulaGraph is a distributed, easily scalable, and native graph database. It is capable of hosting graphs with hundreds of billions of vertices and trillions of edges, and serving queries with millisecond-latency.
With a shared-nothing distributed architecture, NebulaGraph offers linear scalability, meaning that you can add more nodes or services to the cluster without affecting performance. It also means that if you want to horizontally scale out NebulaGraph, you don’t need to change the configuration of the existing nodes. As long as the network bandwidth is sufficient, you can add more nodes without changing anything else.
GQL - The graph query language standard
One of the disadvantages of graph databases was the lack of a standard graph query language like SQL for relational databases.
In the past, you have got Cypher, a declarative graph query language invented by Neo4j; Gremlin, a graph traversal language developed by Apache TinkerPop; and nGQL, NebulaGraph’s SQL-like graph query language.
The lack of a standard in query languages made it difficult to build applications that used different graph databases from different vendors.
However, in the last few years, there has been a lot of research activity in this area and some standardization efforts have been made by the industry.
In September 2019, members of ISO/IEC Joint Technical Committee, which is responsible for international Information Technology standards, proposed a project to create a new standard graph query language (ISO/IEC 39075 Information Technology — Database Languages — GQL). GQL is intended to be a declarative database query language, like SQL.
The GQL project proposal states:
"Using graph as a fundamental representation for data modeling is an emerging approach in data management. In this approach, the data set is modeled as a graph, representing each data entity as a vertex (also called a node) of the graph and each relationship between two entities as an edge between corresponding vertices.> The graph data model has been drawing attention for its unique advantages. Firstly, the graph model can be a natural fit for data sets that have hierarchical, complex, or even arbitrary structures. Such structures can be easily encoded into the graph model as edges. This can be more convenient than the relational model, which requires the normalization of the data set into a set of tables with fixed row types. Secondly, the graph model enables efficient execution of expensive queries or data analytic functions that need to observe multi-hop relationships among data entities, such as reachability queries, shortest or cheapest path queries, or centrality analysis.> There are two graph models in current use: the Resource Description Framework (RDF) model and the Property Graph model. The RDF model has been standardized by W3C in a number of specifications. The Property Graph model, on the other hand, has a multitude of implementations in graph databases, graph algorithms, and graph processing facilities.> However, a common, standardized query language for property graphs (like SQL for relational database systems) is missing. GQL is proposed to fill this void."
It is expected that the GQL standard become available by the end of this year(2022). In June 2022, the GQL Standard website said in an update that “It turns out that writing a database language standards is a lot of work, but we are making progress.”
Just like how SQL provided to a boost to the popularity of relational databases, the availability of GQL standard is also expected to further promote the use of graph database.
Graph database is the future of business intelligence
Graph databases have been around for decades. In recent years, however, they’ve become increasingly popular because they offer new ways of visualizing and analyzing data that can help companies make better decisions about their business processes.
It's not just a buzzword; companies like Facebook, LinkedIn, Google and Twitter are using graph databases to store their data and make sense of it.
Graph databases are a carrier of big data, which makes it possible to process anything you need using an intuitive and effective means; by using information, relational data and non-relational data as input. The graph databases market is now young enough to raise your interest – the future looks very promising for graph databases.
For now, the future of business intelligence appears to be a distinctive blend of "old and new". Relational databases will continue to be widely used but increasingly supplemented with or replaced by graph databases – with the caveat that this switch is not an "either/or" affair. Nor does it represent a radical change in attitude toward data storage: the key lies in adopting an enterprise-wide understanding of data, rather than one based on individual silos.
When should I use graph databases?
You should use graph databases when you need to model huge and highly interconnected data. So if you find yourself facing complex tasks such as connecting data from multiple sources or analyzing intricate relationships between people, groups, events, or concepts, then turn to graph databases.
They provide the flexibility to represent better inter-connectivity between elements and enable quick insights into connections between objects that are not easily modeled in other database systems.
Conclusion
Unlike traditional relational or document-based databases, graph databases provide powerful search capabilities and enable superior performance when performing complex queries on a large dataset. Additionally, graph databases make it much easier for developers to modify data structures without breaking existing applications or creating additional complexity due to changes in schema. Graph databases also boast greater scalability when dealing with high volumes of data whereas traditional systems typically suffer from poor responsiveness under such circumstances.
With these unique advantages, it's no surprise that graph databases are experiencing tremendous growth and becoming the go-to choice for many organizations. They offer tremendous potential for improving how we organize, access, analyze and utilize our ever-growing connected datasets.
Whether your organization handles large volumes of connected customer or product related data, graph databases could provide the crucial bridge you need to move from the isolated silos managed with traditional tools.
FAQ Section
Should I use a graph database?
Yes, you should. Graph databases make it easy to explore relationships between data items, and are also very efficient at handling large quantities of data. They store data in a way that mirrors the structure of the real world, allowing them to quickly find the shortest path between two data points in the graph.
Why are graph databases better than relational databases?
Graph databases are better than relational databases because they are exceptionally good at handling complex data relationships. Relational databases are fundamentally a collection of tables, IDs and values. This approach is great for static data sets where relationships between the data are simple and well-defined. But it’s extremely difficult to use these databases for complex use cases. The more tables you have, the more relational databases will struggle as performance is degraded.
Graph databases, on the other hand, store data in graphs, which makes it easy to represent complex relationships between the data. This means that graph databases can easily handle large amounts of data more efficiently than relational databases. With this in mind, you should not have difficulties choosing between graph databases and relational databases.
Why graph database is a good choice?
A graph database is a good choice because it represents relationships between entities in a simple graph structure. In other words, it's well-suited for representing data with complex relationships.
A graph database can quickly traverse these relationships to find connections between points in the graph. This makes them ideal for complex applications such as fraud detection, network security, and recommendation engines.
