
Use-cases
Use ChatGPT and NebulaGraph Database to Predict FIFA World Cup 2022
An attempt to use ChatGPT to generate code for a data scraper to predict sports events with the help of the NebulaGraph graph database and graph algorithms.
The Hype of ChatGPT
In the hype for FIFA 2022 World Cup, I saw a blog post from Cambridge Intelligence, in which they leveraged limited information and correlations among players, teams, and clubs to predict the final winning team. As a graph technology enthusiast, I always would like to try similar things with NebulaGraph to share the ideas of graph algorithms to extract hidden information from the overall connections in a graph in the community.
The initial attempt was to complete it in about 2 hours, but I noticed the dataset needs to be parsed carefully from Wikipedia and I happened to be not good at doing this job, so I put the idea on hold for a couple of days.
In the meantime, another craze, the OpenAI ChatGPT, was announced. As I had been a user of DALL-E 2 already(to generate feature images of my blog posts), I also gave it a try very quickly. And I witnessed how other guys(via Twitter, blogs, HackerNews) tried to convince ChatGPT to do so many things that are hard to believe they could do:
- Help to implement a piece of code at any time
- Simulate any prompt interface: shell, python, virtual machine, or even a language you create
- Act out almost any given persona, and chat with you
- Write poetry, rap, prose
- Find a bug in a piece of code
- Explain the meaning of a complex regular expression/Open Cypher Query
ChatGPT's ability to contextualize and understand has never been greater before, so much so that everyone is talking about a new way of working: how to master asking/convincing/triggering machines to help us do our jobs better and faster.
So, after trying to get ChatGPT to help me write complex graph database query statements, explain the meaning of complex graph query statements, and a large chunk of Bison code, which he/she had done them WELL, I realized: why not let ChatGPT write the code that extracts the data for me?
Grabbing data
I really tried it and the result is… good enough.
The whole process was basically like a coding interviewer, or a product manager, presenting my requirements, then ChatGPT giving me the code implementation. I then try to run the code, find the things that don't make sense in the code, point them out, and give suggestions, and ChatGPT quickly understands the points I point out and makes the appropriate corrections, like:
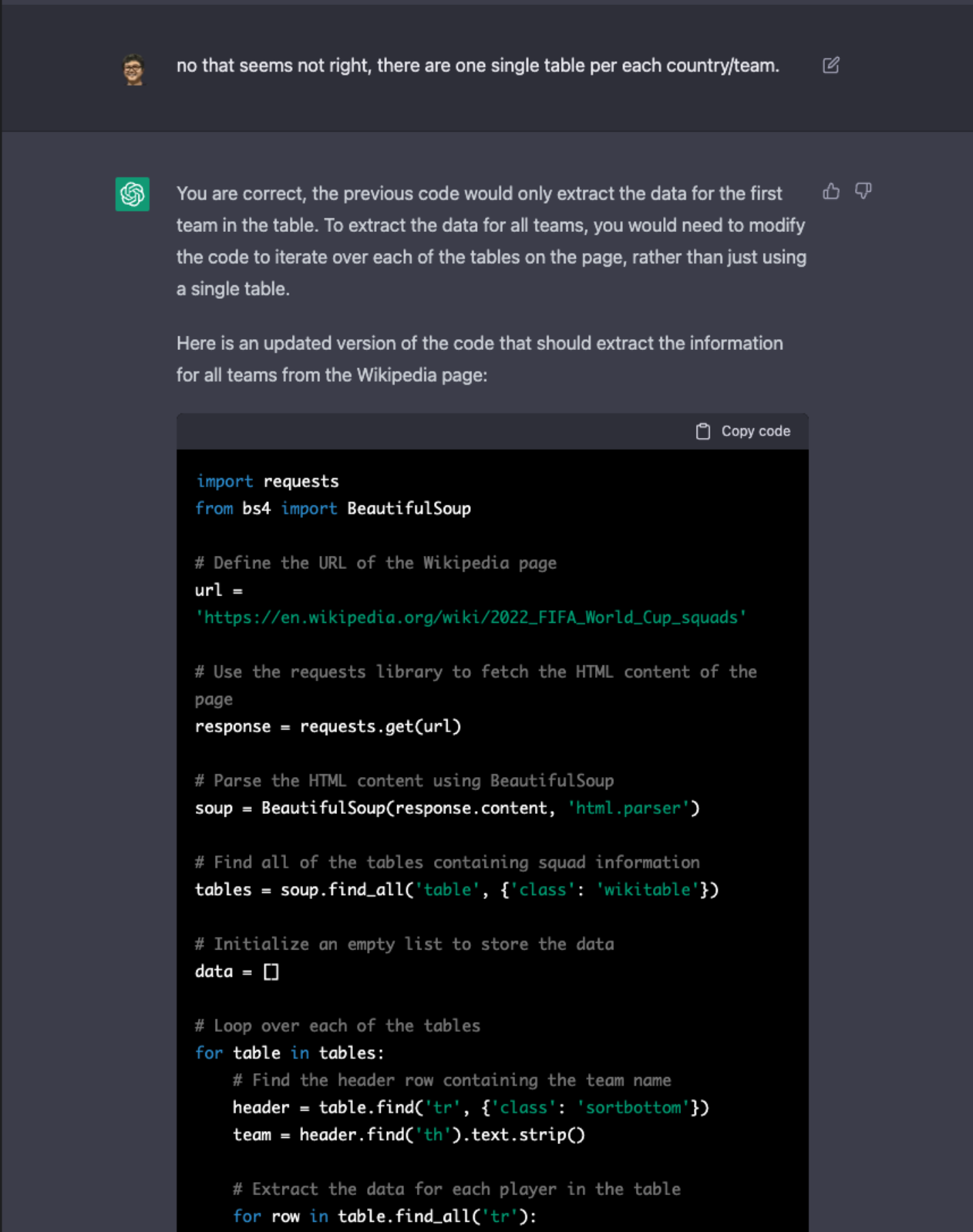
I won't list this whole process, but I share the generated code and the whole discussion here.
The final generated data is a CSV file.
Raw version world_cup_squads.csv
Manually modified, separated columns for birthday and age world_cup_squads_v0.csv
It contains information/columns of a team, group, number, position, player name, birthday, age, number of international matches played, number of goals scored, and club served.
Team,Group,No.,Pos.,Player,DOB,Age,Caps,Goals,Club
Ecuador,A,1,1GK,Hernán Galíndez,(1987-03-30)30 March 1987,35,12,0,Aucas
Ecuador,A,2,2DF,Félix Torres,(1997-01-11)11 January 1997,25,17,2,Santos Laguna
Ecuador,A,3,2DF,Piero Hincapié,(2002-01-09)9 January 2002,20,21,1,Bayer Leverkusen
Ecuador,A,4,2DF,Robert Arboleda,(1991-10-22)22 October 1991,31,33,2,São Paulo
Ecuador,A,5,3MF,José Cifuentes,(1999-03-12)12 March 1999,23,11,0,Los Angeles FC
- Final version with header removed world_cup_squads_no_headers.csv
Graph algorithm to predict the FIFA World Cup 2022
With the help of ChatGPT, I could finally try to predict the winner of the game with Graph Magic, before that, I need to map the data into the graph view.
If you don't care about the process, go to the predicted result directly.
Graph modeling
Prerequisites: This article uses NebulaGraph(Open-Source) and NebulaGraph Explorer(Proprietary), which you can request a free trial of on AWS.
Graph Modeling is the abstraction and representation of real-world information in the form of a "vertex-> edge" graph. In our case, we will project the information parsed from Wikipedia as:
Vertices:
- player
- team
- group
- club
Edges:
- groupedin (the team belongs to which group)
- belongto (players belong to the national team)
- serve (players serve in the club)
The age of the players, the number of international caps, and the number of goals scored are naturally fit as properties for the player tag(type of vertex).
The following is a screenshot of this schema in NebulaGraph Explorer (I will just call it Explorer later).
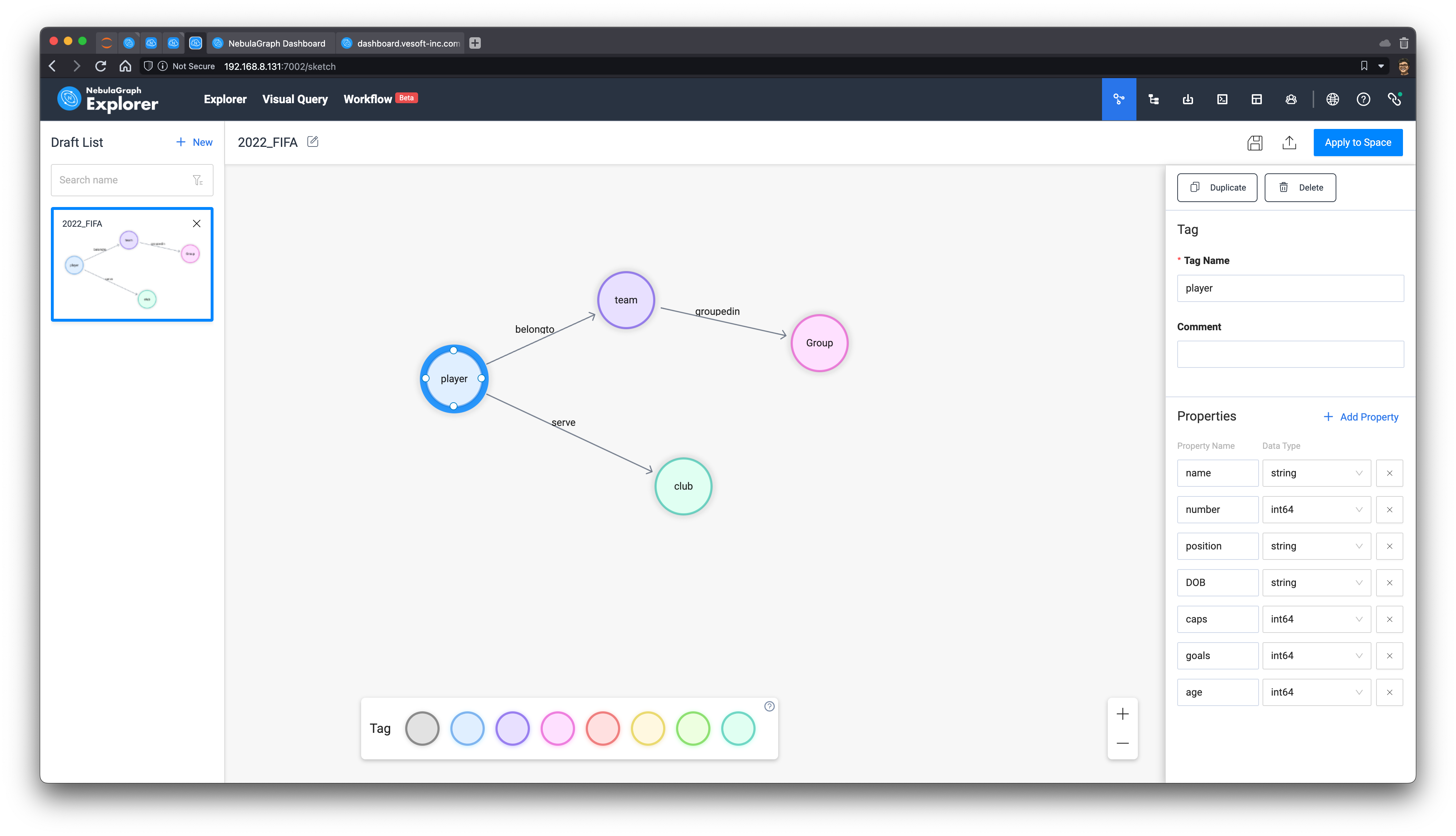
Then, we can click the save icon in the upper right corner and the button: Apply to Space to create a graph space with the defined schema:
Ingesting into NebulaGraph
With the graph modeling, we can upload the CSV file (the no-header version) into Explorer, by pointing and selecting the vid and properties that map the different columns to the vertices and edges.
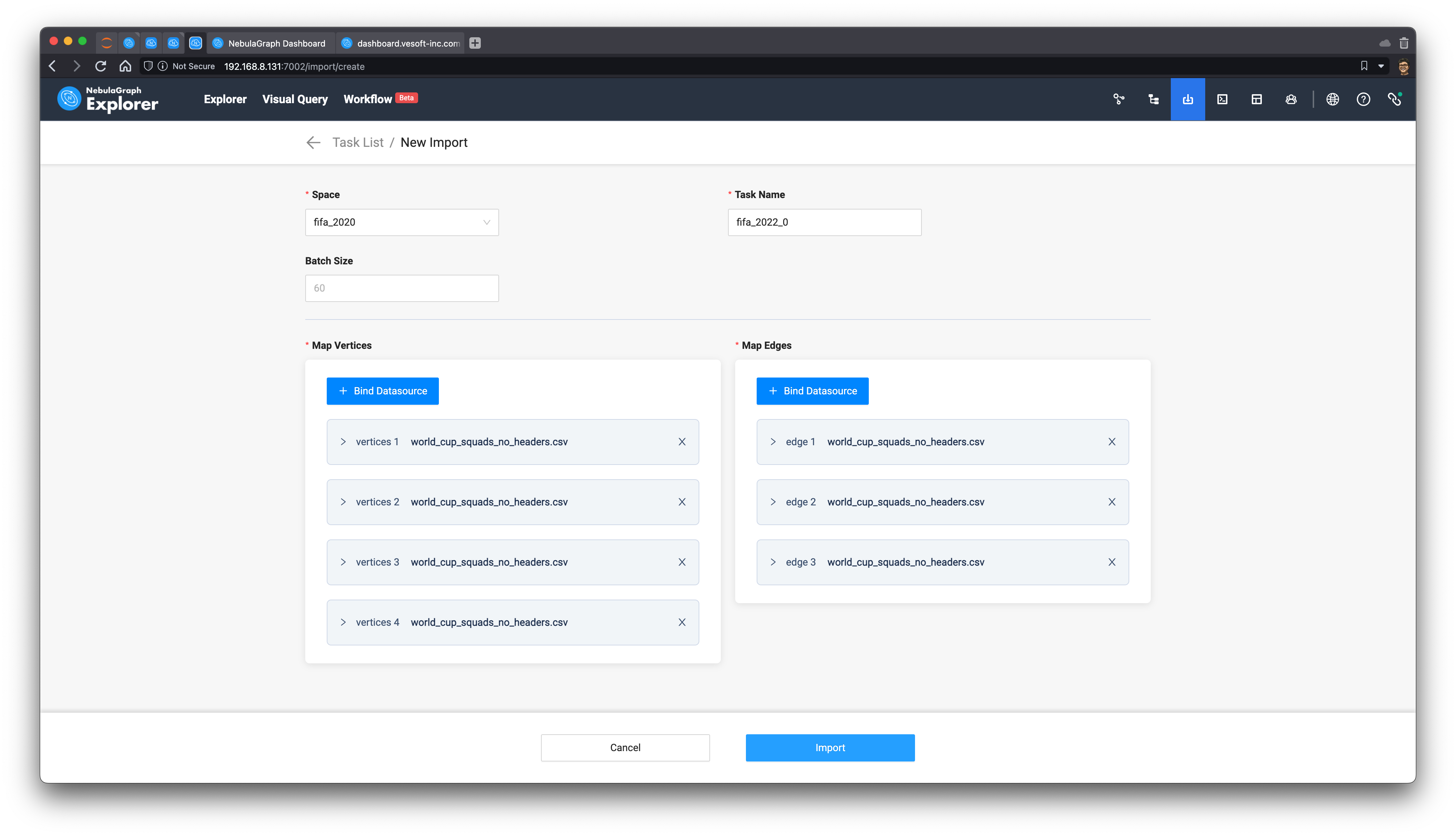
Click Import, we then import the whole graph to NebulaGraph, and after it succeeded, we could also get the entire CSV --> Nebula Importer configuration file: nebula_importer_config_fifa.yml, so that you reuse it in the future whenever to re-import the same data or share it with others.
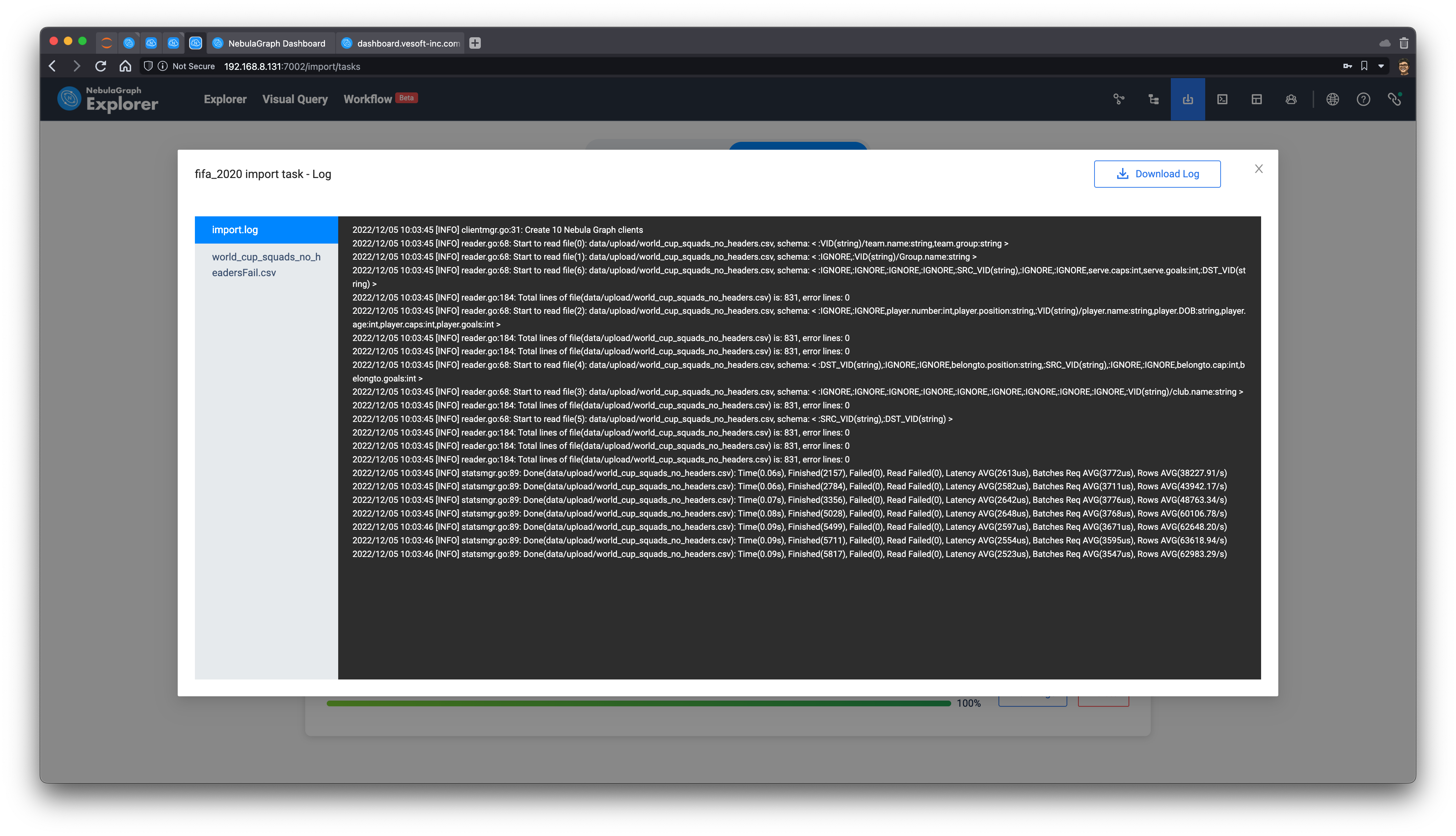
Note: Refer to the Import Data Document
After importing, we can view the statistics on the schema view page, showing us that 831 players participated in the 2022 Qatar World Cup, serving in 295 different clubs.
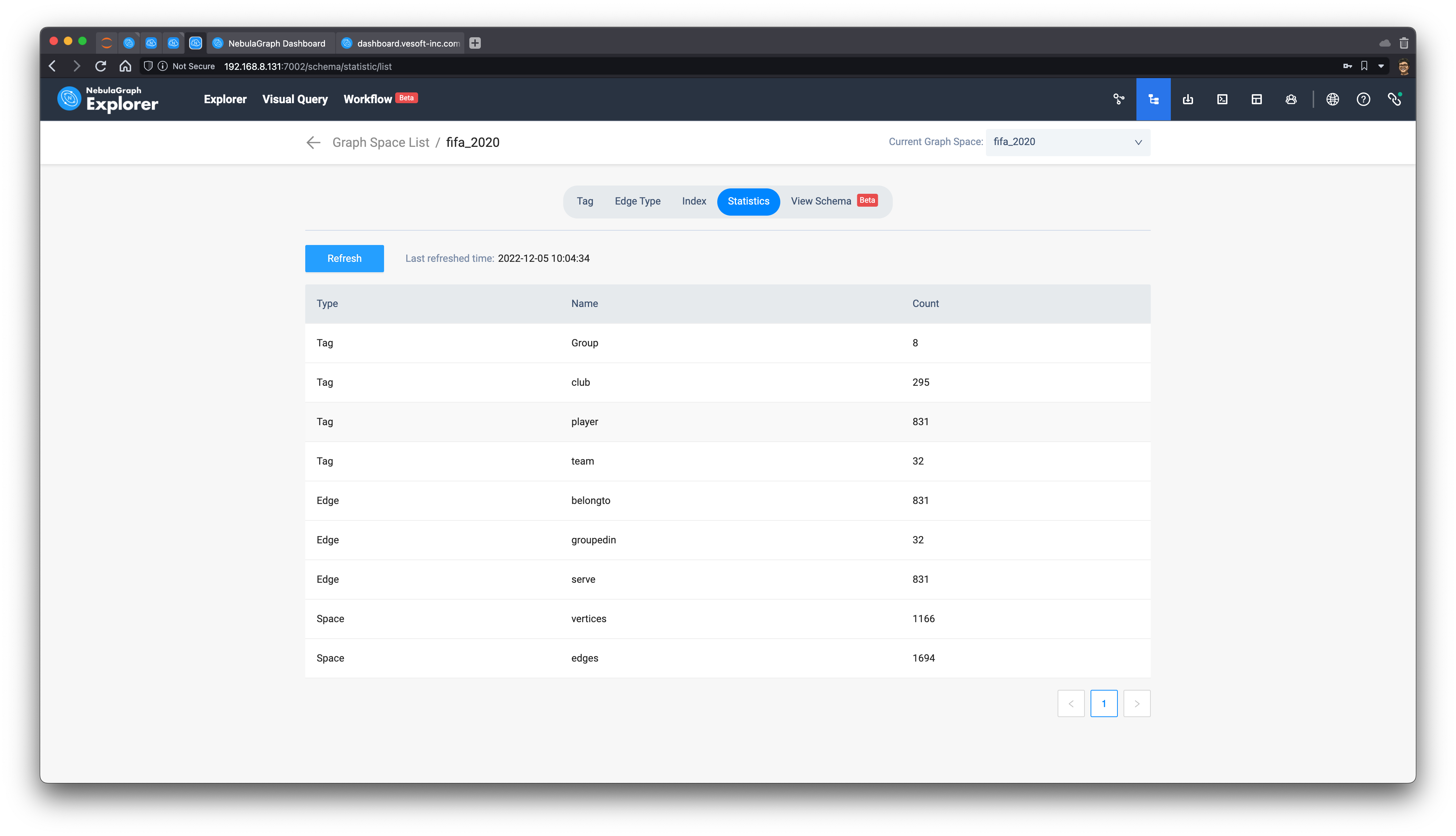
Explore the graph
Let's see what insights we could get from the information/ knowledge in the form of a graph.
Querying the data
Let's start by showing all the data and see what we will get.
First, with the help of NebulaGraph Explorer, I simply did drag and drop to draw any type of vertex type (TAG) and any type of edge between vertex types (TAG), here we know that all the vertices are connected with others, so no isolated vertices will be missed by this query pattern:
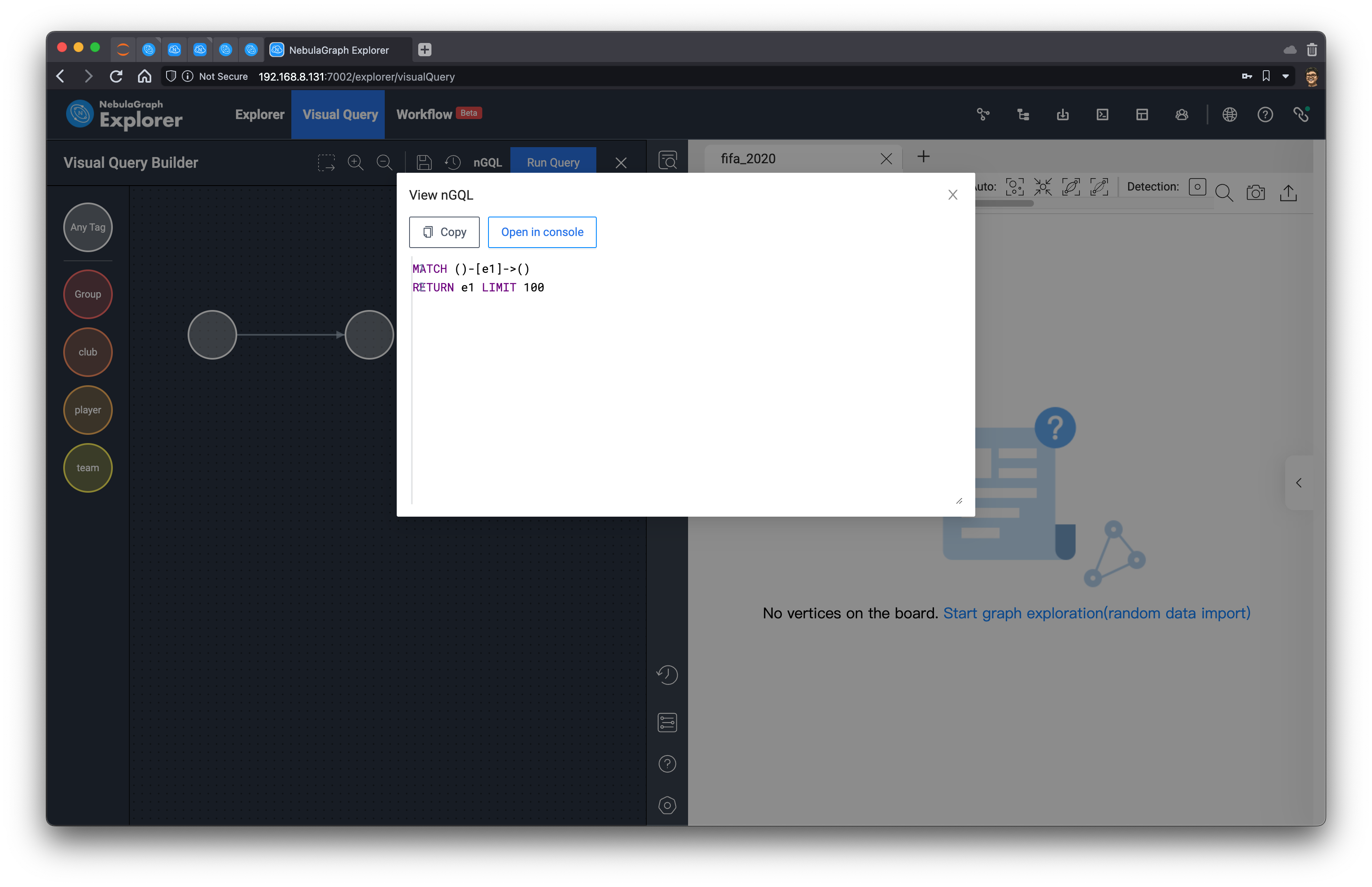
Let it generate the query statement for me. Here, it defaults to LIMIT 100, so let's change it to something larger (LIMIT 10000) and let it execute in the Console.
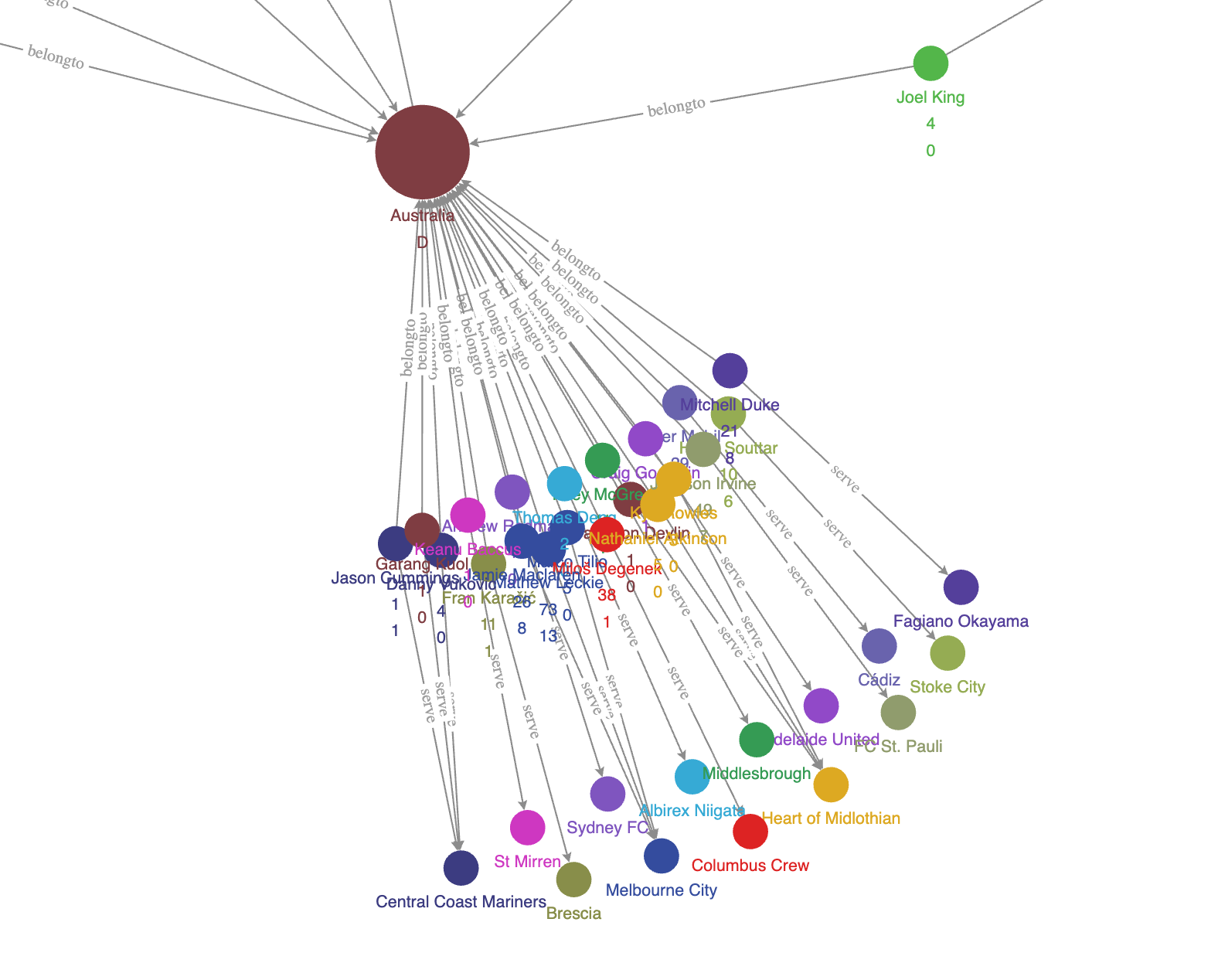
Initial observation
The result renders out like this, and you can see that it naturally forms a pattern of clusters.
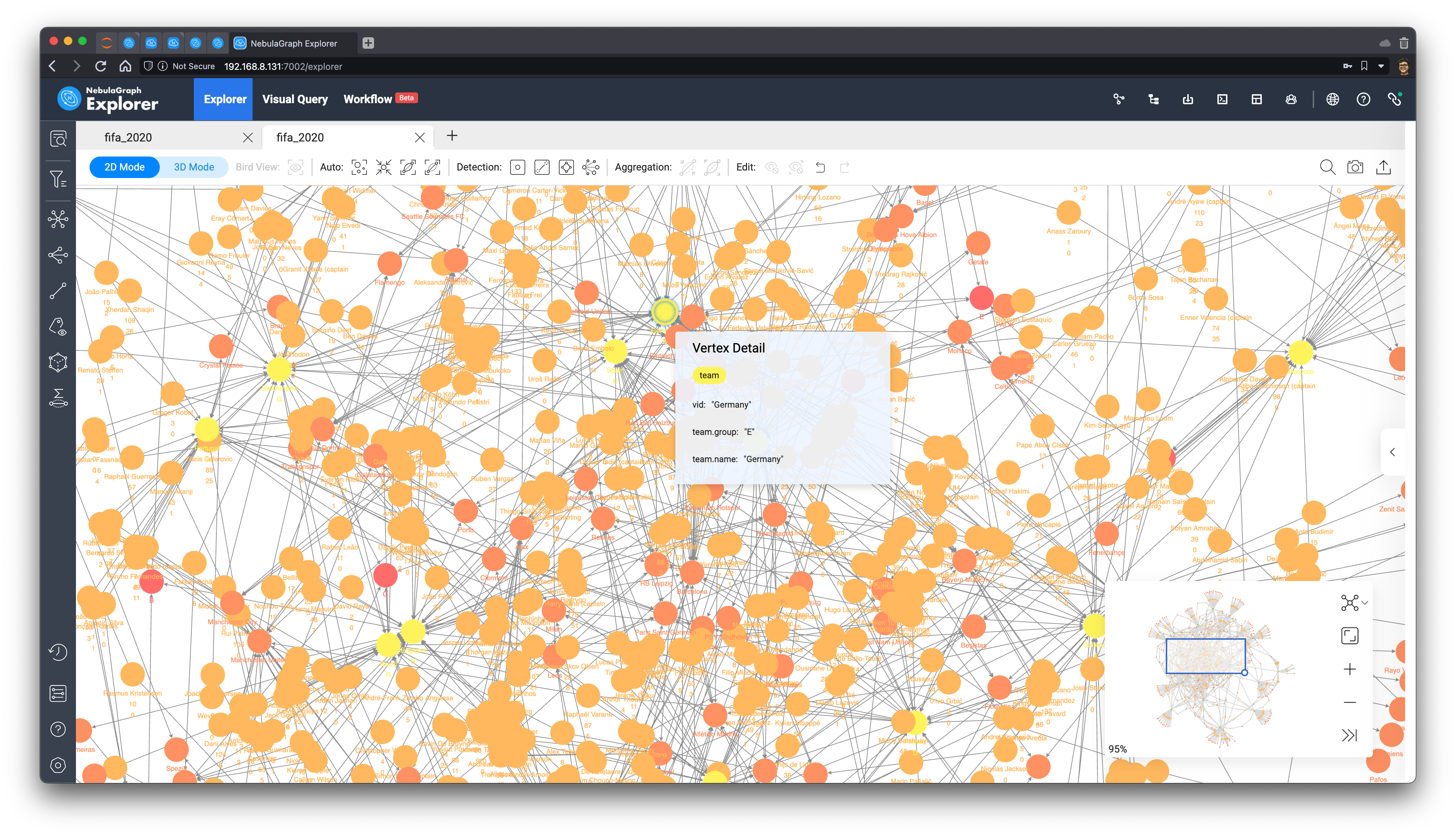
These peripheral clusters are mostly made up of players from clubs that are not traditionally strong ones (now we learned that they could win, though, who knows!). Many of those clubs have only one or two players who serve in one national team or region, so they are somewhat isolated from other clusters.
Graph algorithm-based analysis
After I clicked on the two buttons(Sized by Degrees, Colored by Louvain Algorithm) in Explorer (refer to the document for details), in the browser, we can see that the entire graph has become something like this:
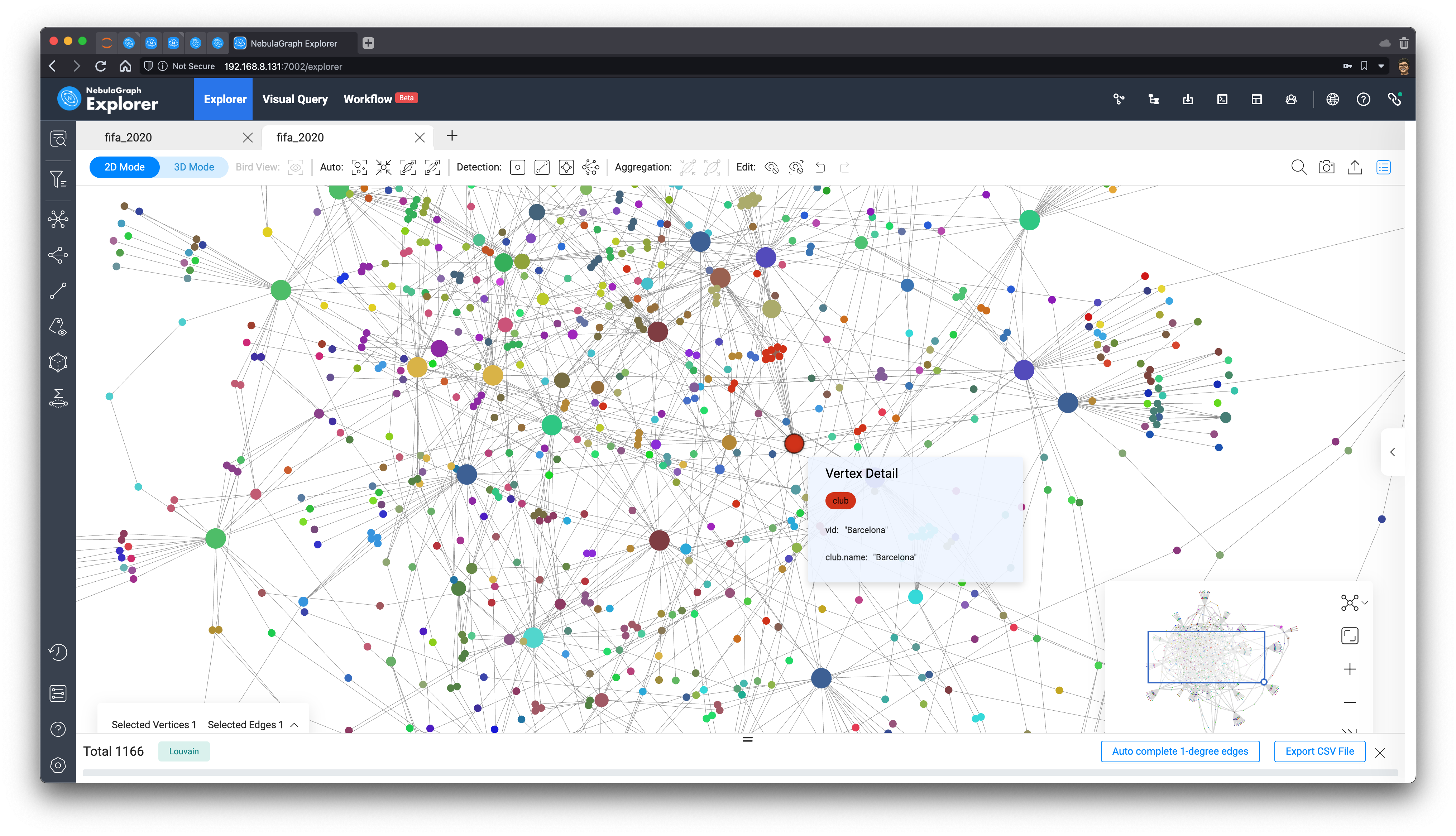
Two graph algorithms are utilized to analyze the insights here.
- change the display size of vertices to highlight importance using their degrees
- using Louvain's algorithm to distinguish the community of the vertices
You can see that the big red circle is the famous Barcelona, and its players are marked in red, too.
Winner Prediction Algorithm
In order to be able to make full use of the graph magic(with the implied conditions and information on the graph), my idea(stolen/inspired from this post) is to choose a graph algorithm that considers edges for node importance analysis, to find out the vertices that have higher importance, iterate and rank them globally, and thus get the top team rankings.
These methods actually reflect the fact that excellent players have greater community and connectivity at the same time. Meanwhile, to increase the differentiation between traditionally strong teams, I am going to take into account the information on appearances and goals scored.
Ultimately, my algorithm is:
- Take all the
(player)-serve->(club)relationships and filter them for players with too few goals and too few goals per game (to balance out the disproportionate impact of older players from some weaker teams) - Explore outwards from all filtered players to get national teams
- Run the Betweenness Centrality algorithm on the above subgraph to calculate the node importance scores
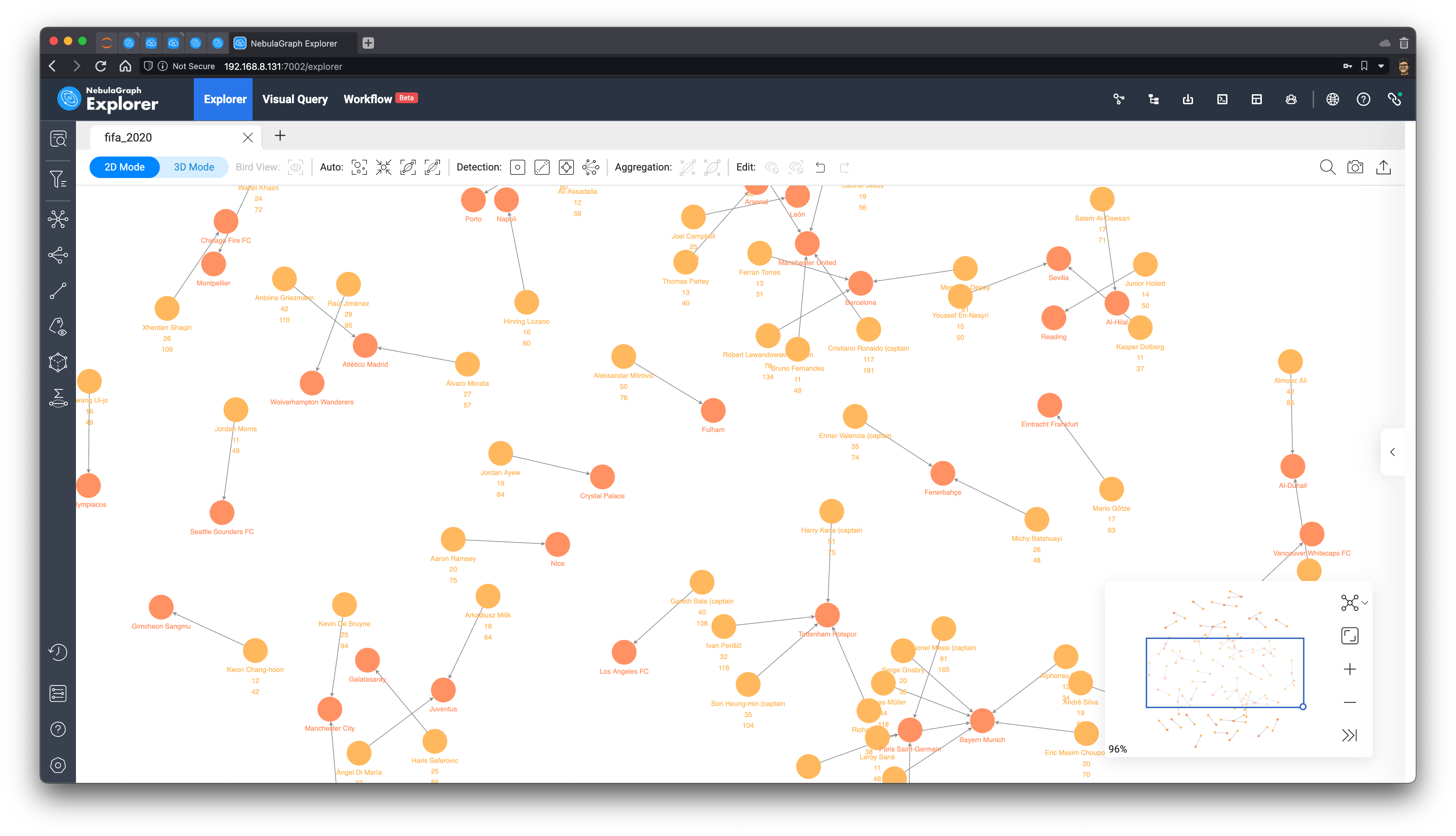
Process of the Prediction
First, we take out the subgraph in the pattern of (player)-serve->(club) for those who have scored more than ten goals and have an average of more than 0.2 goals per game.
MATCH ()-[e]->()
WITH e LIMIT 10000
WITH e AS e WHERE e.goals > 10 AND toFloat(e.goals)/e.caps > 0.2
RETURN e
Note: For convenience, I have included the number of goals and caps as properties in the serve edge, too.
Then, we select all the vertices on the graph in the left toolbar, select the belongto edge of the outgoing direction, expand the graph outwards (traverse), and select the icon that marks the newly expanded vertices as flags.
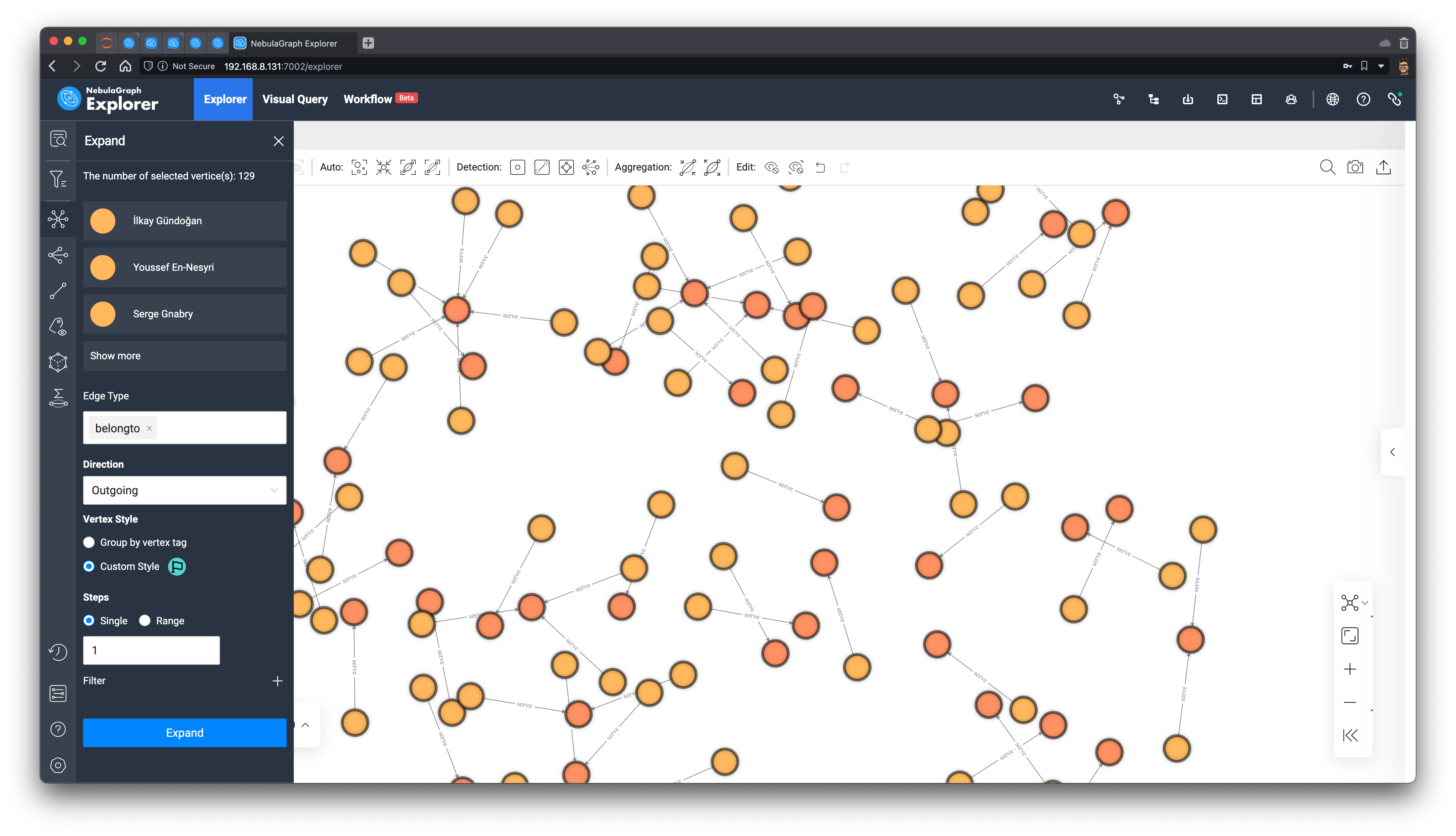
Now that we have the final subgraph, we use the graph algorithm function within the browser to execute BNC (Betweenness Centrality):
The graph canvas then looks like this:
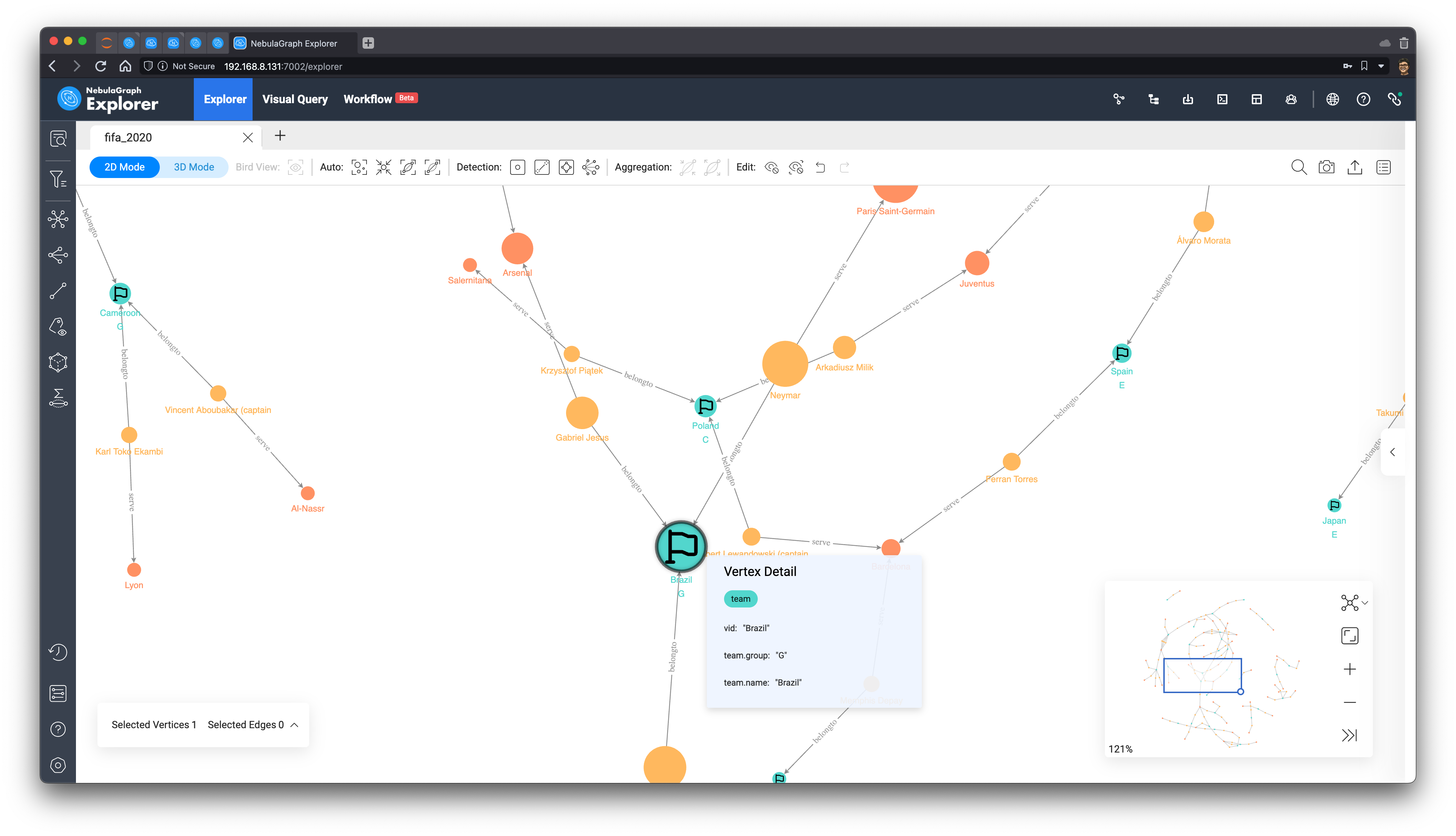
Result
Ultimately, we sorted according to the value of Betweenness Centrality to get the final winning team: Brazil! 🇧🇷, followed by Belgium, Germany, England, France, and Argentina, so let's wait two weeks to come back and see if the prediction is accurate :D.
The sorted data is as follows:
| Vertex | Betweenness Centrality |
|---|---|
| Brazil🇧🇷 | 3499 |
| Paris Saint-Germain | 3073.3333333333300 |
| Neymar | 3000 |
| Tottenham Hotspur | 2740 |
| Belgium🇧🇪 | 2587.833333333330 |
| Richarlison | 2541 |
| Kevin De Bruyne | 2184 |
| Manchester City | 2125 |
| İlkay Gündoğan | 2064 |
| Germany🇩🇪 | 2046 |
| Harry Kane (captain | 1869 |
| England🏴 | 1864 |
| France🇫🇷 | 1858.6666666666700 |
| Argentina🇦🇷 | 1834.6666666666700 |
| Bayern Munich | 1567 |
| Kylian Mbappé | 1535.3333333333300 |
| Lionel Messi (captain | 1535.3333333333300 |
| Gabriel Jesus | 1344 |
Feature Image Credit: The image was also generated with OpenAI, through the DALL-E 2 model & DALL-E 2 Outpainting. See the original image.




{kind=link}