Case Studies
Jan 12, 2023
7 Fundamental Use Cases of Social Networks with NebulaGraph Database | EP 3
Wey Gu
In this third episode of our series on social network analysis using graph databases, we will delve deeper into the power of this technology to uncover insights about our networks. Building upon the concepts introduced in previous episodes, such as identifying key people, determining the closeness between two users, and recommending new friends, we will now explore new techniques for pinpointing important content using common neighbors, pushing information flow based on friend relationships and geographic location, and using spatio-temporal relationship mapping to query the relationship between people. We will also look at how this technology can be used to identify the provinces visited by a group of people who intersected in time and space.
Common Neighbor
Finding common neighbors is a very common graph database query, and its scenarios may bring different scenarios depending on different neighbor relationships and node types. The common buddy in the first two scenarios is essentially a common neighbor between two points, and directly querying such a relationship is very simple with OpenCypher.
A common neighbor between two vertices
For example, this expression can query the commonality, intersection between two users, the result may be common teams, places visited, interests, common participation in post replies, etc.:.
And after limiting the type of edge, this query is limited to the common friend query.
Common neighbors among multiple vertices: content notification
Below, we give a multi-nodes common neighbor scenario where we trigger from a post, find out all the users who have interacted on this post, and find the common neighbors in this group.
What is the use of this common neighbor? Naturally, if this common neighbor has not yet had any interaction with this article, we can recommend this article to him.
The implementation of this query is interesting.
The first MATCH is to find the total number of people who left comments and authors on all post11 articles
After the second MATCH, we find the number of friends of the interacting users who have participated in the article that is exactly equal to the number of users who have participated in the article, and they are actually the common friends of all the participating users.
And that person is . . Tony!
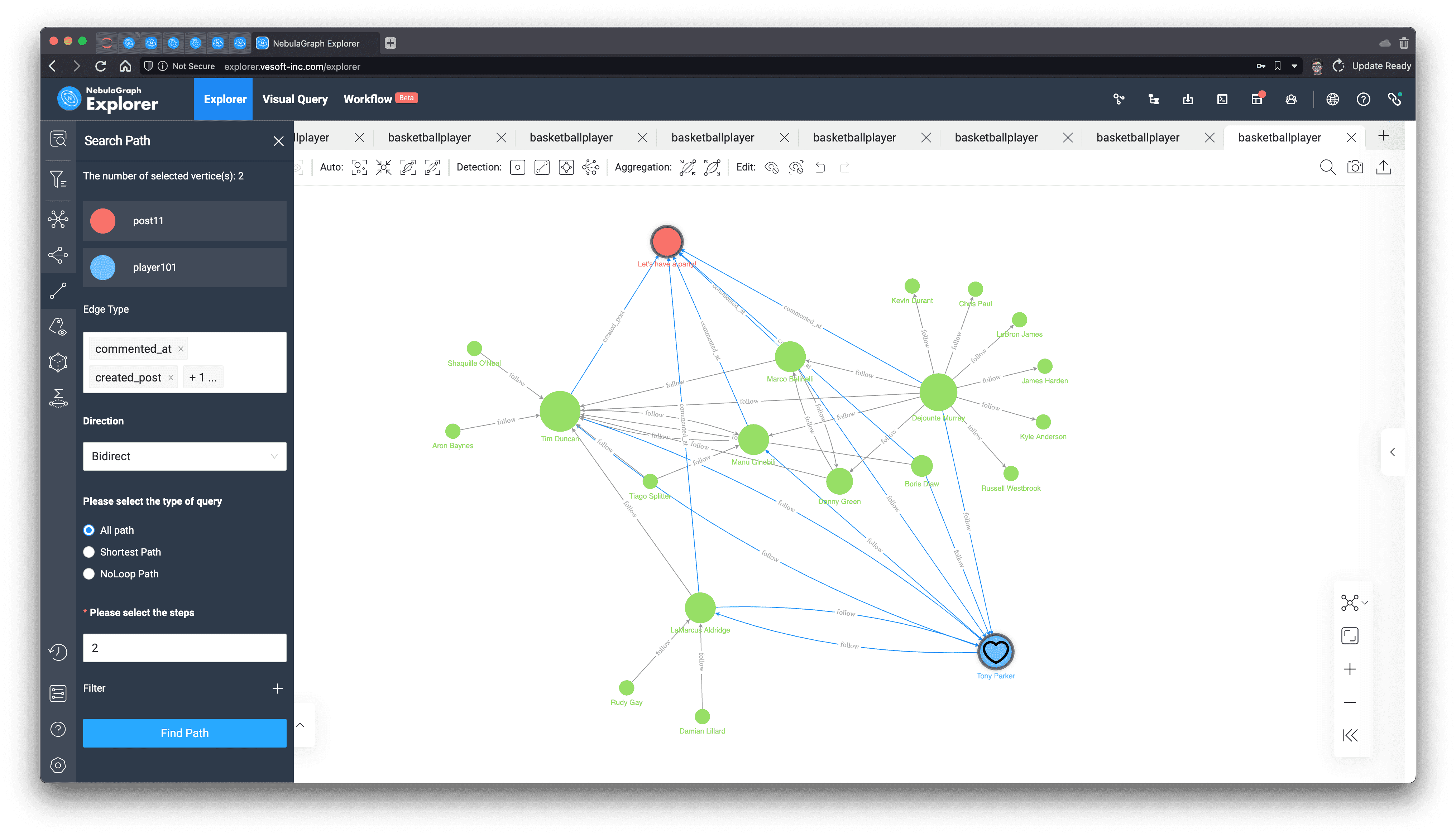
And we can easily verify it in the visualization of the query:
Rendering this query, and then looking for two-way, two-hop queries between the article called "Let's have a party!" and Tony's comments, posts, and followers, we can see that all the people involved in the article are, without exception, Tony's friends, and only Tony himself has not yet left a comment on the article!
And how can a party be without Tony? Is it his surprise birthday party, Opps, shouldn't we tell him, or?
Feed Generation
I have previously written about the implementation of recommendation systems based on graph technology, in which I described that content filtering and sorting methods in modern recommendation systems can be performed on graphs. It is also highly time-sensitive. The feed generation in a SNS is quite similar but slightly different.
Content with friend engagement
The simplest and most straightforward definition of content generation may be the facebook feed of content created and engaged by people you follow.
Content created by friends within a certain period of time
the content of friends' comments within a certain time frame
We can use OpenCypher to express this query for the stream of information with user id player100.
friend.player.name | feeds |
|---|---|
Boris Diaw | ["I love you, Mom", "comment of post11"] |
Marco Belinelli | ["my best friend, tom", "comment of post11"] |
Danny Green | ["comment of post1"] |
Tiago Splitter | ["comment of post1"] |
Dejounte Murray | ["comment of post11"] |
Tony Parker | ["I can swim"] |
LaMarcus Aldridge | ["I hate coriander", "comment of post11", "comment of post1"] |
Manu Ginobili | ["my best friend, jerry", "comment of post11", "comment of post11"] |
So, we can send these comments, articles to the user's feed.
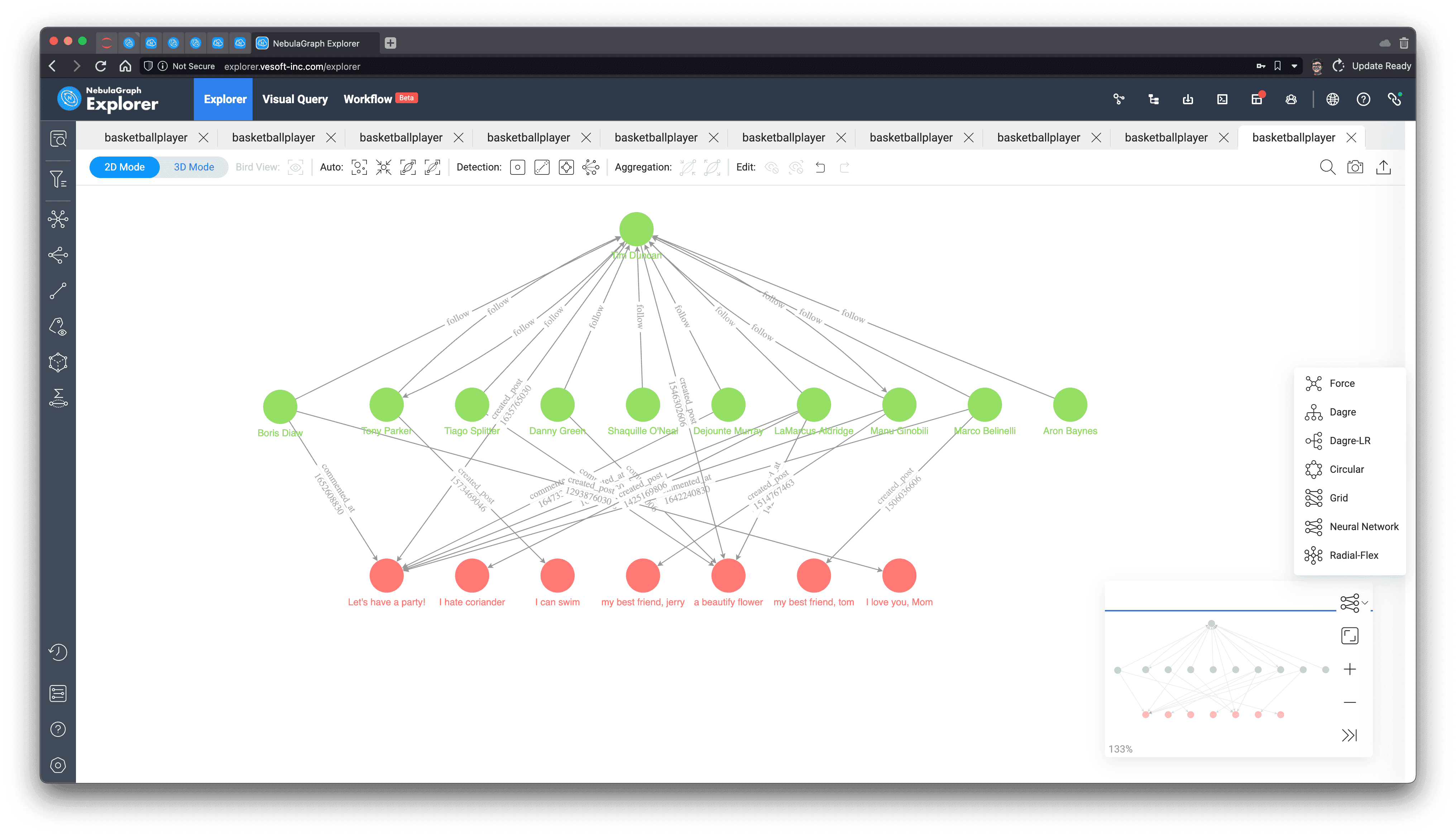
Let's also see what they look like on the graph, we output all the paths we queried:
Rendering on Explorer and selecting the "Neural Network" layout, you can clearly see the pink article nodes and the edges representing the comments.
Content of nearby friends
Let's go a step further and take geographic information(GeoSpatial) into account to get content related to friends whose addresses have a latitude and longitude less than a certain distance.
Here, we use NebulaGraph's GeoSpatial geography function, the constraint ST_Distance(home.address.geo_point, friend_addr.address.geo_point) AS distance WHERE distance < 1000000 helps us express the distance limit.
friend.player.name | feeds |
|---|---|
Marco Belinelli | ["my best friend, tom", "comment of post11"] |
Tony Parker | ["I can swim"] |
Danny Green | ["comment of post1"] |
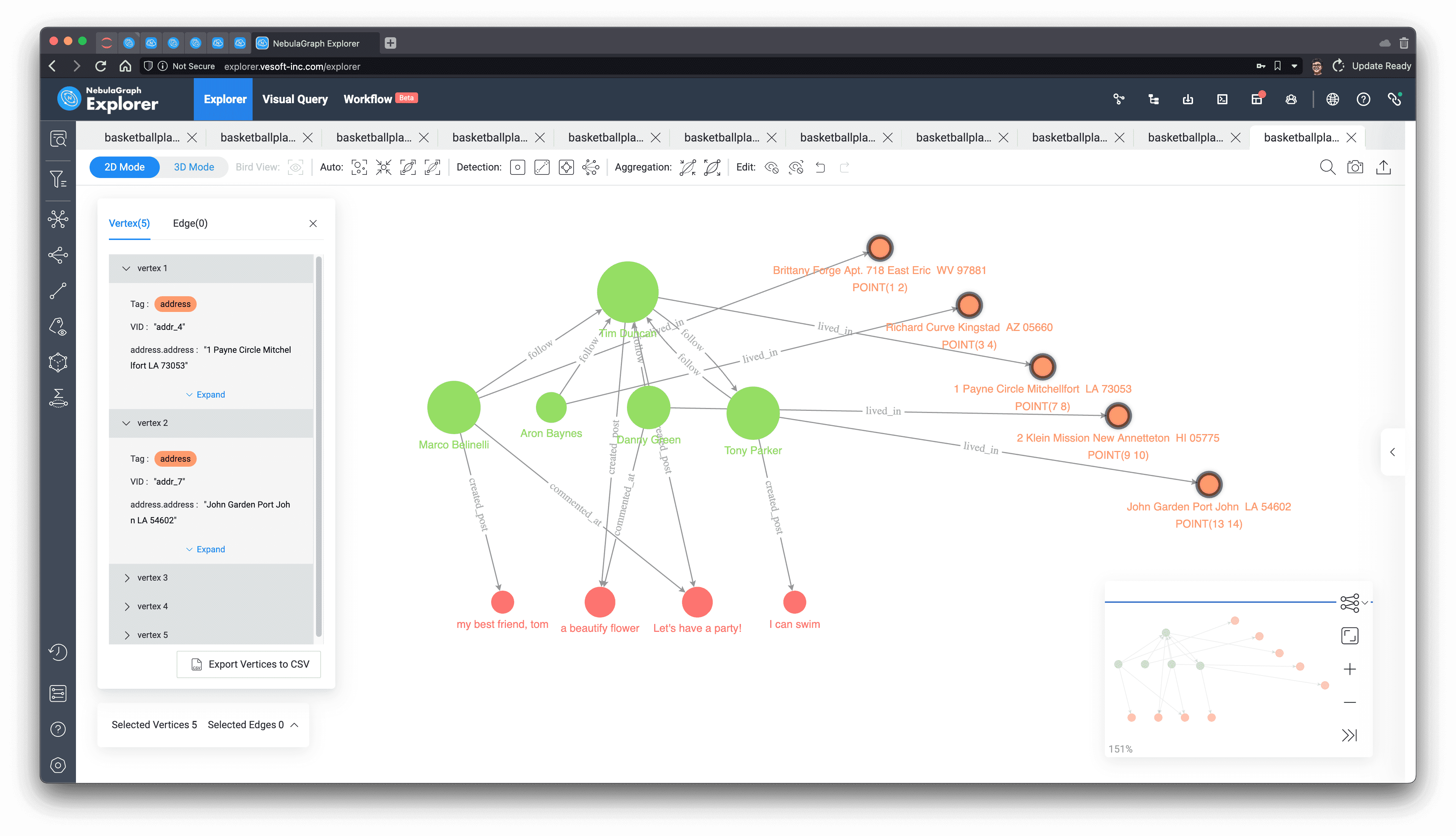
At this point, you can also see the relationship between addresses and their latitude and longitude information from the visualization of this result.
I manually arranged the nodes of the addresses on the graph according to their latitude and longitude and saw that the address (7, 8) of Tim(player100), the owner of this feed, is exactly in the middle of other friends' addresses.
Spatio-temporal relationship tracking
Spatio-temporal relationship tracking is a typical application that uses graph traversal to make the most of complicated and messy information in scenarios such as public safety, logistics, and epidemic prevention and control. When we build such a graph, we often need only simple graph queries to gain very useful insights. In this section, I'll give an example of this application scenario.
Dataset
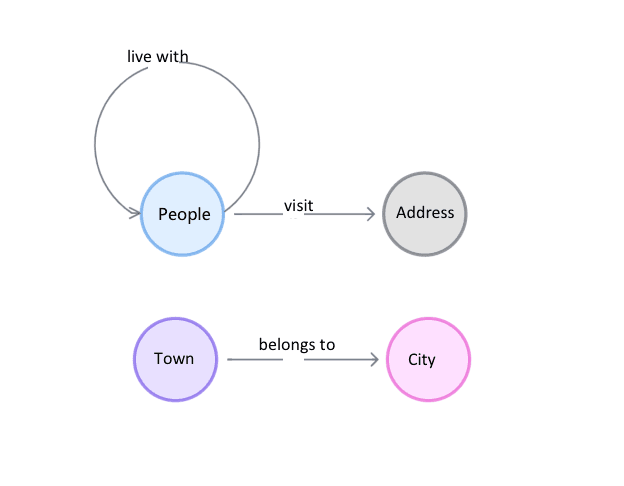
For this purpose, I created a fake dataset by which to build a spatio-temporal relationship graph. The dataset generation program and a file that can be used directly are placed on GitHub at https://github.com/wey-gu/covid-track-graph-datagen.
It models the data as follows.
We could get the data ready in three lines in any Linux System:
Then we could inspect the data from console:
Results:
Connections between two
This could be done with FIND PATH
SHORTEST Path result:
paths |
|---|
<("p_100")<-[:live with@0 {}]-("p_2136")<-[:live with@0 {}]-("p_3708")-[:visit@0 {}]->("a_125")<-[:visit@0 {}]-("p_101")> |
ALL Path result:
paths |
|---|
<("p_100")<-[:live with@0 {}]-("p_2136")<-[:live with@0 {}]-("p_3708")-[:visit@0 {}]->("a_125")<-[:visit@0 {}]-("p_101")> |
<("p_100")-[:visit@0 {}]->("a_328")<-[:visit@0 {}]-("p_6976")<-[:visit@0 {}]-("p_261")-[:visit@0 {}]->("a_352")<-[:visit@0 {}]-("p_101")> |
<("p_100")-[:visit@0 {}]->("p_8709")-[:visit@0 {}]->("p_9315")-[:live with@0 {}]->("p_261")-[:visit@0 {}]->("a_352")<-[:visit@0 {}]-("p_101")> |
<("p_100")-[:visit@0 {}]->("a_328")<-[:visit@0 {}]-("p_6311")-[:live with@0 {}]->("p_3941")-[:visit@0 {}]->("a_345")<-[:visit@0 {}]-("p_101")> |
<("p_100")-[:visit@0 {}]->("a_328")<-[:visit@0 {}]-("p_5046")-[:live with@0 {}]->("p_3993")-[:visit@0 {}]->("a_144")<-[:live with@0 {}]-("p_101")> |
<("p_100")-[:live with@0 {}]->("p_3457")-[:visit@0 {}]->("a_199")<-[:vvisit@0 {}]-("p_6771")-[:visit@0 {}]->("a_458")<-[:visit@0 {}]-("p_101")> |
<("p_100")<-[:live with@0 {}]-("p_1462")-[:visit@0 {}]->("a_922")<-[:vvisit@0 {}]-("p_5869")-[:visit@0 {}]->("a_345")<-[:visit@0 {}]-("p_101")> |
<("p_100")<-[:live with@0 {}]-("p_9489")-[:visit@0 {}]->("a_985")<-[:vvisit@0 {}]-("p_2733")-[:visit@0 {}]->("a_458")<-[:visit@0 {}]-("p_101")> |
<("p_100")<-[:visit@0 {}]-("p_9489")-[:visit@0 {}]->("a_905")<-[:visit@0 {}]-("p_2733")-[:visit@0 {}]->("a_458")<-[:visit@0 {}]-("p_101")> |
<("p_100")-[:visit@0 {}]->("a_89")<-[:visit@0 {}]-("p_1333")<-[:visit@0 {}]-("p_1683")-[:visit@0 {}]->("a_345")<-[:visit@0 {}]-("p_101")> |
We render all the paths visually, mark the two people at the starting node and end end, and check their shortest paths in between, and the inextricable relationship between them is clear at a glance, whether it is for business insight, public safety or epidemic prevention and control purposes, with this information, the corresponding work can progress downward like a tiger.
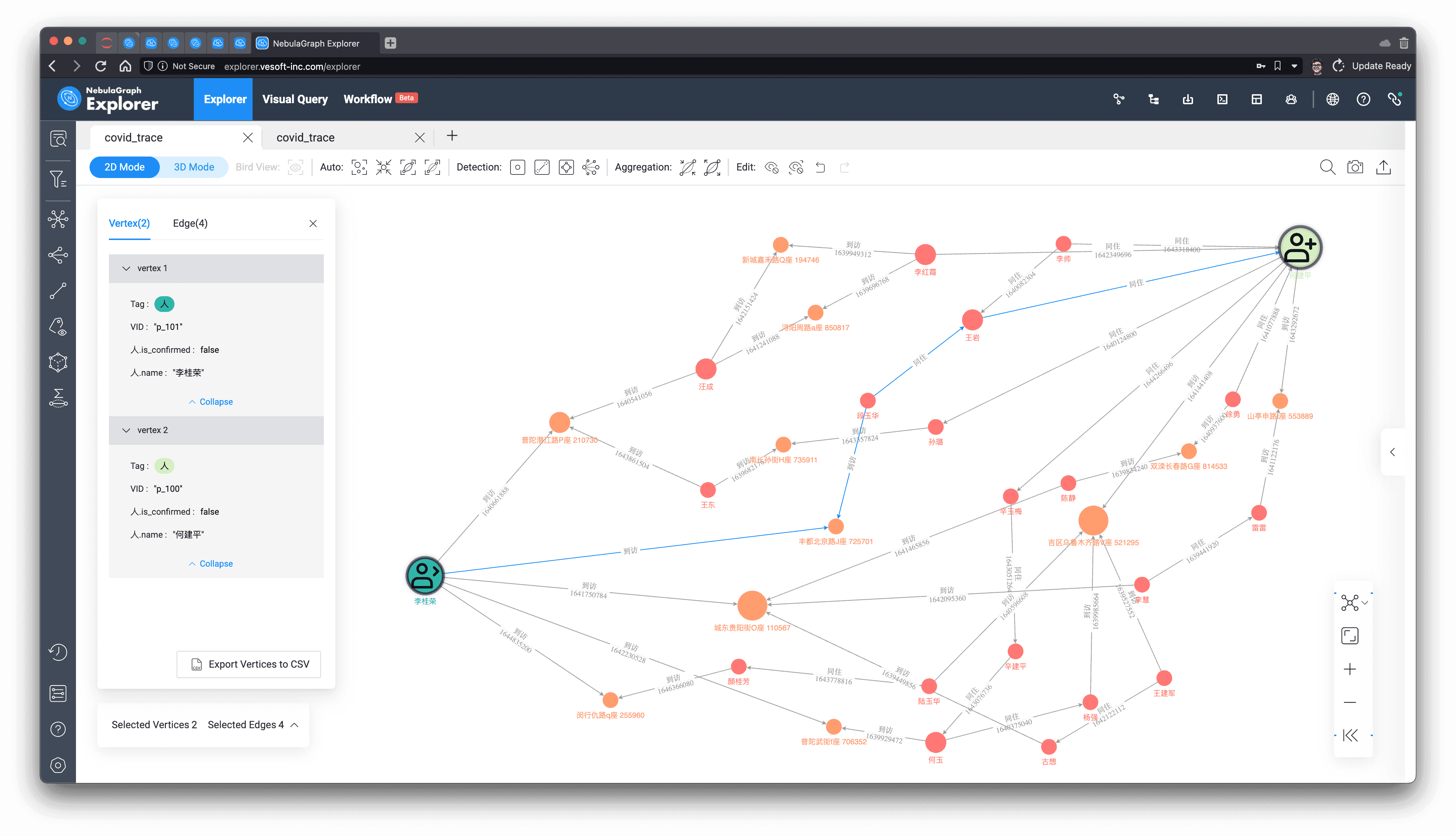
Of course, on a real world system, it may be that we only need to care about the proximity of the association between two users:
In the result we only care about the length of the shortest path between them as: 4.
len |
|---|
4 |
Temporal intersection of people
Further we can use graph semantics to outline any patterns with temporal and spatial information that we want to identify and query them in real time in the graph, e.g. for a given person whose id is p_101, we differ all the people who have temporal and spatial intersection with him at a given time, which means that those people also stay and visit a place within the time period in which p_101 visits those places.
We obtained the following list of temporal intersection people at each visited location.
addr.address.name | collect(p1.person.name) |
|---|---|
闵行仇路q座 255960 | ["徐畅", "王佳", "曾亮", "姜桂香", "邵秀英", "韦婷婷", "陶玉", "马坤", "黄想", "张秀芳", "颜桂芳", "张洋"] |
丰都北京路J座 725701 | ["陈春梅", "施婷婷", "井成", "范文", "王楠", "尚明", "薛秀珍", "宋金凤", "杨雪", "邓丽华", "李杨", "温佳", "叶玉", "周明", "王桂珍", "段玉华", "金成", "黄鑫", "邬兵", "魏柳", "王兰英", "杨柳"] |
普陀潜江路P座 210730 | ["储平", "洪红霞", "沈玉英", "王洁", "董玉英", "邓凤英", "谢海燕", "梁雷", "张畅", "任玉兰", "贾宇", "汪成", "孙琴", "纪红梅", "王欣", "陈兵", "张成", "王东", "谷霞", "林成"] |
普陀武街f座 706352 | ["邢成", "张建军", "张鑫", "戴涛", "蔡洋", "汪燕", "尹亮", "何利", "何玉", "周波", "金秀珍", "杨波", "张帅", "周柳", "马云", "张建华", "王丽丽", "陈丽", "万萍"] |
城东贵阳街O座 110567 | ["李洁", "陈静", "王建国", "方淑华", "古想", "漆萍", "詹桂花", "王成", "李慧", "孙娜", "马伟", "谢杰", "王鹏", "鞠桂英", "莫桂英", "汪雷", "黄彬", "李玉梅", "祝红梅"] |
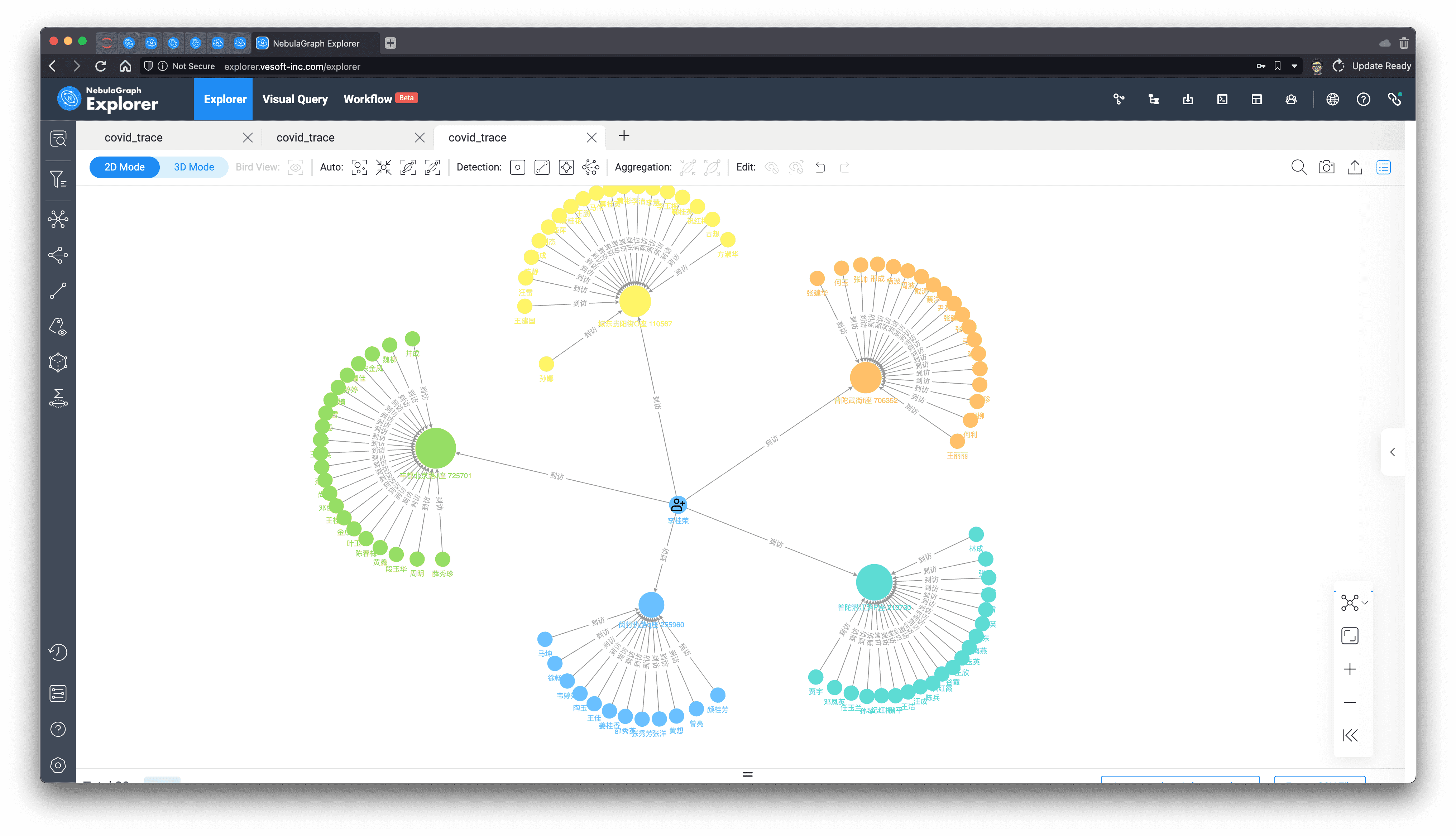
Now, let's visualize this result on a graph:
In the result, we marked p_101 as a different icon, and identified the gathering community with the label propagation algorithm, isn't a graph worth a thousand words?
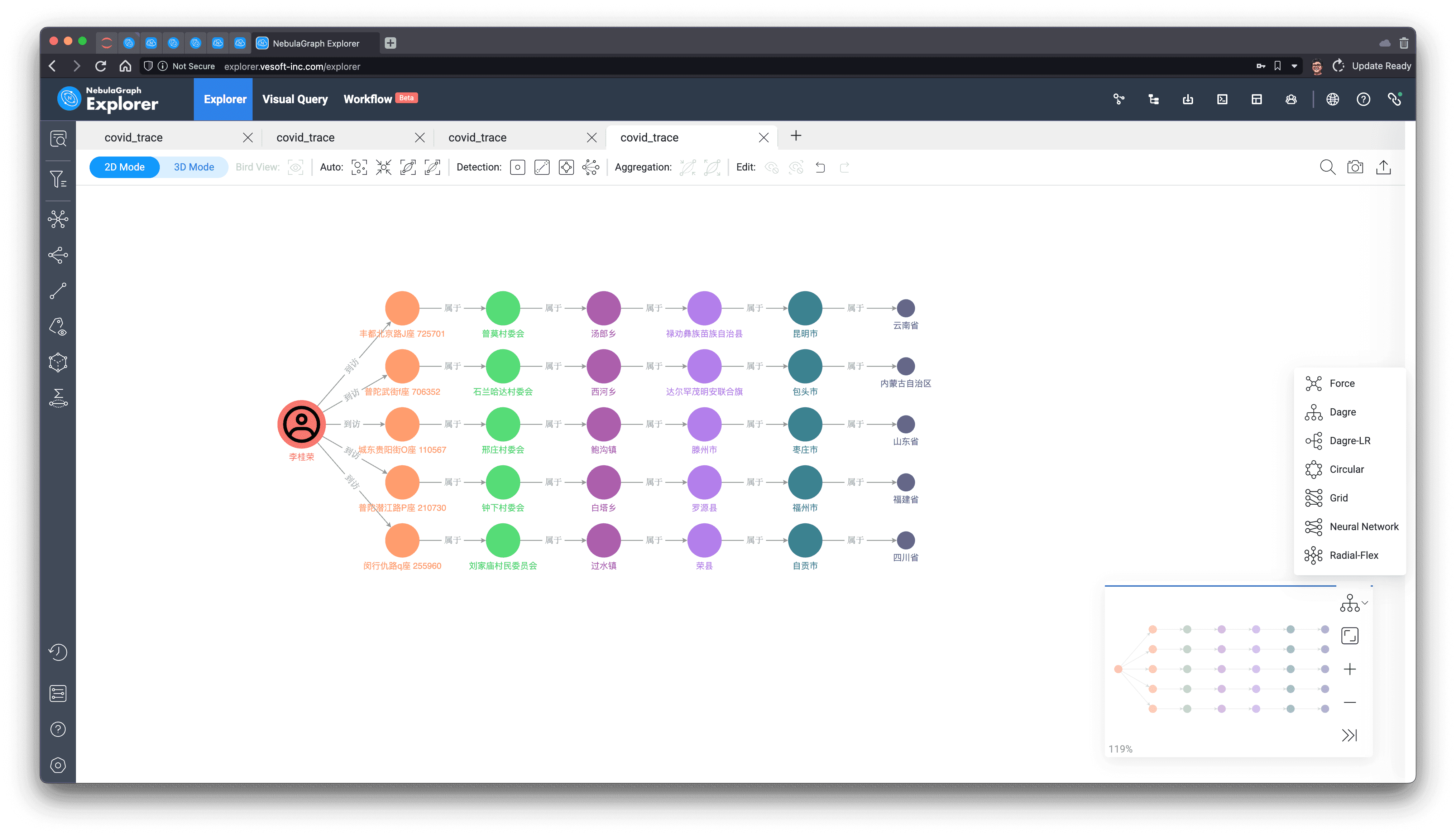
Most recently visited provinces
Finally, we then use a simple query pattern to express all the provinces a person has visited in a given time, say from a point in time:
Result:
prov.province.name | collect(addr.address.name) |
|---|---|
四川省 | ["闵行仇路q座 255960"] |
山东省 | ["城东贵阳街O座 110567"] |
云南省 | ["丰都北京路J座 725701"] |
福建省 | ["普陀潜江路P座 210730"] |
内蒙古自治区 | ["普陀武街f座 706352"] |
The usual rules, let's look at the results on the graph, this time, we choose Dagre-LR layout rendering, and the result looks like:
Recap
We have given quite a few examples of applications in social networks, including
As a natural graph structure, social networks are well suited to use graph technology to store, query, compute, analyze and visualize to solve various problems on them. We hope you can have a preliminary understanding of the graph technology in SNS through this post.
How NebulaGraph Works
[

](javascript:window.open('https://bit.ly/3XHS873'))
